摘要
脉冲神经网络(SNN)具有强大的时空信息表征、异步事件处理能力, 但由于脉冲发放过程不具有连续可微性, 其训练是一个难题. 人工神经网络(ANN)转SNN的方法, 能够获得较高推理精度的深度SNN, 但却存在SNN网络延迟和功耗过高的问题. 为了降低网络延迟和功耗, 本文从脉冲信息传递的异步特性入手, 分析了极低延迟下SNN 精度损失的主要原因, 提出残余膜电位误差(RMPE)的概念, 并对其进行分析与推导, 建立残余膜电位与初始膜电位和权重之间的关系模型. 基于所建立的残余膜电位模型, 提出一种初始膜电位和权重的分层校准算法, 减少残余膜电位误差, 从而解决脉冲输入序列均匀分布假设与真实分布不一致的问题. 提出一种ANN-SNN的双阶段转化框架, 在第1阶段, 采用带有可训练分层阈值的量化截断激活函数对ANN进行二次训练, 以实现量化误差与截断误差的最优化; 在第2阶段, 对SNN进行微调训练, 以进一步缩小残余膜电位误差, 使得在极低延迟下的ANN-SNN转化也能获得较高的精度. 实验结果表明, 本文方法在推理延迟和功耗方面都优于现有的方法.
Abstract
Spiking neural network (SNN) possesses robust capabilities for spatiotemporal information representation and asynchronous event processing. However, training SNN is challenging due to the non-differentiable nature of the spiking process. Converting artificial neural network (ANN) to SNN can yield deep SNN with high inference accuracy, but this approach often results in increased latency and power consumption in SNN. To mitigate network latency and power consumption, we have analyzed the primary reasons behind the loss of SNN accuracy at ultra-low latency, focusing on the asynchronous transfer characteristics of spikes. We introduce the concept of residual membrane potential error (RMPE) to address these issues. We have analyzed and derived the relationship between residual membrane potential and both the initial membrane potential and weights. Based on this understanding, we propose a layer-by-layer calibration algorithm for adjusting initial membrane potential and weights, aiming to reduce residual membrane potential error. This approach resolves the discrepancy between the assumption of a uniform distribution of spike input trains and the actual distribution. We propose a two-stage conversion framework for ANN-to-SNN conversion. In the first stage, we employ a quantization clipping activation function with a trainable stratification threshold. This allows us to train the ANN twice, optimizing both quantization error and clipping error. In the second stage, we further fine-tune the SNN to reduce residual membrane potential errors at ultra-low latency. Experimental results demonstrate that our proposed method outperforms existing methods in terms of inference latency and power consumption.
Keywords
1 引言
脉冲神经网络(spiking neural network,SNN)包含具有时序动力学特性的神经元节点、稳态–可塑性平衡的突触结构、功能特异性的网络环路,高度借鉴了生物启发的局部非监督、全局弱监督的生物优化方法,具有强大的时空信息表征、异步事件处理能力. 其被部署在具有神经形态芯片的硬件上时,将具有深度人工神经网络(artificial neural network,ANN)无法企及的低功耗、低延迟和强大的计算力 [1-2] .
尽管SNN具有上述优点,但由于脉冲神经元的脉冲发放过程不具有连续可微性,深度学习中的梯度下降算法不能直接应用于SNN的训练,因此,SNN的训练仍然是一个难题. 针对这一问题,有研究者提出了使用时间依赖可塑性(spike-timing-dependent-plasticity,STDP)[3-4] 和替代梯度(surrogate gradient,SG)[5-6] 方法来训练SNN,但这两种方法训练得到的SNN的精度较低,且对梯度消失和梯度爆炸现象更为敏感,因此很难实现对深层 SNN的训练. 为了获得更高精度的SNN,Cao等人 [7] 提出将训练好的深度ANN转化为对应深度SNN的方法,目前这种基于ANN-SNN转化获得深度SNN的方法已成为构建高精度SNN的首选方法. ANN-SNN转化的基本原理是: 首先,使用监督学习训练ANN,然后,将训练好的ANN参数迁移到具有相同网络结构的SNN. 由于SNN的脉冲神经元与ANN的模拟神经元在信息表示和传递机制方面存在巨大差异,由训练好的ANN转化得到的SNN与源ANN 之间存在近似误差. 因此,后续研究主要集中在近似误差的消除等方面. 这些方法,按照神经元信息编码方式的不同可分为两类: 基于时间编码的方法 [8-9] 和基于速率编码的方法. 其中,速率编码 [10-13] 利用神经元的脉冲发放率来表征和识别特征,相对于时间编码,具有编码简单和鲁棒性强等优点,故在ANN-SNN转化中被广泛使用. 这类方法主要通过优化SNN的权重阈值比降低近似误差,或对ANN-SNN转化误差建模,找到与之有关的SNN参数,从而进行针对性的参数优化来降低近似误差.
调整SNN参数以降低近似误差的方法,主要针对 SNN的网络权值、脉冲发放阈值、初始膜电位等参数进行调整,以使SNN的输出尽可能接近ANN的输出. Diehl等人 [11] 将ANN中每一层的最大激活值作为归一化尺度因子,提出权值归一化方法,优化了SNN的权重阈值比,从而降低了SNN神经元发放率饱和所产生的近似误差. 但因为异常激活值的存在,深层次网络神经元的脉冲发放率极低,使得大量的脉冲神经元处于失活状态. 为此,Rueckauer等人 [12] 分析了16666个 CIFAR-10样本,发现99.9%的修正线性单元(rectified linear unit,ReLU)激活值远远小于最大激活值,基于此,提出了99.9百分位阈值方法,以解决异常值所导致的深层网络脉冲神经元失活的问题. Ho和Ding等人 [14-15] 在ANN中添加可训练的裁剪层,利用尺度因子缩放激活值,然后将缩放后的激活值映射到SNN的阈值,从而更好平衡网络的精度与延迟性能. 上述方法虽然不同程度上降低了SNN与ANN之间的近似误差,但由于这些方法仅考虑了激活值的截断误差,往往需要设置很长的推理时间窗口(大于1000个时间步),才能达到与ANN相接近的分类精度,而这将导致SNN丧失其低延迟优势.
为此,研究者通过对ANN-SNN转化过程进行深入的研究,对近似误差进行建模,以获得与近似误差有关的参数,从而对相关参数进行针对性地优化. 研究者 [16-18] 推导出了可分层优化的转化损失函数,发现量化误差和截断误差与初始膜电位的偏移量有关,基于SNN输入符合均匀分布这一假设,通过分层分解近似误差调整初始膜电位的最佳偏移量,在一定程度上减少了SNN的推理延迟. Bu等人 [19] 推导估计了SNN 的激活函数,将转化误差分为截断误差、量化误差和不均匀误差. 该方法首先假设剩余膜电位v l(T)在[0,Vth),将不均匀误差归为量化误差. 然后,假设脉冲神经元输入的脉冲序列符合均匀分布,提出以量化截断移位激活函数替换ReLU激活函数,在ANN中训练 SNN各层阈值的方法. 最后,在转化得到的SNN中,将初始膜电位统一设置为. 上述方法虽然一定程度上降低了SNN的推理延迟,但有研究 [20] 表明: 该类方法所提出的SNN输入符合均匀分布这一假设过于简单,甚至是错误的,导致其在极低延迟时(如,T = 4),往往会有较大的精度损失. 另一方面,由脉冲信息传递的异步性可知,脉冲神经元在时间步T结束之后的残余膜电位v l(T)的值可能为负数,或者超过阈值,因此,将其值限制在[0,Vth)是不合理的. 再者,直接采用量化截断移位激活函数替换ReLU函数进行ANN训练 [19],会导致训练得到的ANN存在较大的精度波动.
针对上述问题,本文分析了极低延迟下SNN精度损失的主要原因,提出残余膜电位误差(residual membrane potential error,RMPE)的概念,从脉冲神经元输入输出发放率之间的关系,分析残余膜电位误差与初始膜电位和权重之间的关系,通过分层校准算法校准初始膜电位和权重来减少残余膜电位误差,从而解决SNN输入均匀分布假设与真实分布不一致的问题. 此外,针对直接使用量化截断移位激活函数替代ReLU激活函数,进行ANN训练导致其精度波动变大的问题,本文提出一种双阶段转化框架: 第1阶段,首先基于ReLU激活函数预训练ANN,然后,再采用可训练分层阈值的量化激活函数替代ReLU进行ANN的微调,得到与源ANN精度相当的量化–截断ANN(quanti-zation-clipping ANN,QC-ANN),作为预训练SNN. 第 2阶段,通过对预训练SNN的初始膜电位和权重进行分层校准以减少膜电位残余信息误差,得到最终的 SNN. 本文主要贡献总结如下: 1)分析了极低延迟下 SNN精度损失的主要原因,提出残余膜电位误差(RMPE)的概念,并对其进行分析与推导,建立残余膜电位与初始膜电位和权重之间的关系模型; 2)提出一种初始膜电位和权重的分层校准算法,减少残余膜电位误差,从而解决脉冲输入序列均匀分布假设与真实分布不一致的问题; 3)提出一种ANN-SNN的双阶段转化框架,实现量化误差与截断误差的最优化; 进一步缩小残余膜电位误差,使得在极低延迟下的ANN-SNN 转化也能获得较高的精度.
2 IF神经元脉冲响应特性及转化误差分析
2.1 脉冲神经元模型及ANN-SNN转化原理
本文选择集成–发放(integrate-and-fire,IF)模型作为SNN神经元模型. 为了避免信息丢失,本文使用减法复位(reset-by-subtraction)[12] 机制. 一旦膜电位v l (t)超过预先设置的阈值神经元将发放脉冲并更新膜电位v l (t). 因此,膜电位更新的数学形式为
(1)
其中: x l−1(t)表示l − 1层突触前神经元在t时刻的加权突触后膜电位; Wl为突触权值; s l (t)表示l层所有神经元在t时刻的输出脉冲,其值为1表示发放脉冲,为0则表示不发放脉冲,脉冲发放函数是Heaviside阶跃函数(Heaviside step function).
基于速率编码的ANN-SNN转化,其基本思想是假设SNN在一段时间T内的脉冲发放率可以近似等于 ANN的激活值,如式(2)所示:
(2)
2.2 IF神经元脉冲响应特性
本文从SNN的脉冲响应特性出发,根据脉冲神经元接受输入的增量来显式表示输出值,假设 ANN与 SNN在网络l层的输入是相同的,即
为了方便,本文记
用来表示 SNN的脉冲发放率与阈值的乘积. 假设 v l(0)= 0,根据速率编码特性,每个时间步最多发放一个脉冲,即,根据式(2),理想情况下,脉冲个数等于膜电位增量向下取整,如,因此,可以得到
(3)
(4)
其中⌊·⌋表示floor函数. 如式(3)所示,SNN的IF神经元脉冲响应特性可以表示为一个阶梯函数(如图1(a)中的IF阶梯曲线).
2.3 ANN-SNN转化误差分析
ANN的前向传播方程如图1(a)蓝色曲线所示. 由于SNN的输出是离散值,并且是floor的形式,而ANN 的输出是连续值,因此将ANN转化为SNN后导致不可避免的信息损失. 研究表明,ANN激活值与SNN阈值之间存在一个映射关系,当然而,ANN输出a l属于范围如果如图1和式(3)所示,存在信息表示不对等的误差,本文称其为截断误差(clipping error,CE). 由于输出脉冲是离散的,因此式(3)本质上是个量化函数,量化因子为如图1所示,当将激活值a l量化到ϕ l(T)时,不可避免会产生量化误差(quantization error,QE). 从式(3)可知,量化误差和截断误差与阈值有关,且两种误差之间存在一种此消彼长关系,即当阈值单调增加时,会减少截断误差,但会导致量化误差增大. 当阈值单调减少时,会减少量化误差,但会导致截断误差增大. 因此,现有研究 [14-15] 主要集中在如何调整阈值,早期的方法,如Max Norm和Robust Norm [11-12] 等,将ANN 中最大的激活值或最大激活值的 99.9%位值对应于 SNN的阈值,采用固定阈值的方式,来实现ANN-SNN 的转换. 较近的方法,如可训练阶段层(trainable clipping layers,TCL)[14] 等方法,在ANN训练的ReLU层增加一层截断操作,设置一个可训练参数作为最大激活值的缩放因子,缩放后的最大激活值对应于SNN 的阈值,采用可训练阈值来实现ANN-SNN的转换,目的是最小化转换误差,包括截断误差和量化误差,以使得二者之和最小.
2.4 残余膜电位误差分析与推导
现有研究均未考虑脉冲发放的异步性与ANN数据同步性之间存在差异的问题,该问题将导致极短时间步内发放的脉冲数与ANN的激活值存在不一致性.ANN神经元间传递的是实数值,而SNN神经元间传递的是脉冲序列. ANN神经元的信息处理没有时间概念,而SNN神经元的信息处理是以时间步为单位,逐个时间步进行脉冲处理. 脉冲的时序性使得相同频率可能会产生不同顺序的脉冲序列,从而其所对应的SNN输出也不同. 即在频率编码模式下,相同的实数值可能被编码为不同的脉冲序列,其所对应的输出值和原始的ANN实数值之间很可能存在误差. 为此,本文从脉冲信息传递的异步和时序特性入手,分析极低延迟下SNN精度损失的主要原因,以之为基础,提出残余膜电位误差(RMPE)的概念,并对其进行分析与推导.
脉冲发放具有时序性,在较少的时间步内,极易出现脉冲数和激活值不一致的情况,会产生更多或更少的误差脉冲数,这是导致在极低延迟下精度损失的主要原因. 如图1(b)所示,在第1行的例子中,假设输入到ANN中的数据x1 = 2和x2 = 3,对应的权重为w1 = 1和w2 = −1,ANN神经元输出的激活值为0. 在第2 行的例子中,假设输入到ANN中的数据为x1 = 1和 x2 = 1,对应的权重为w1 = 1和w2 = 1,ANN神经元输出的激活值为2. 根据速率编码的特性,将SNN发放脉冲个数与 ANN 激活值相对应,并以某种分布来表示,本文将时间步和阈值分别设置为T = 5,Vth = 1.

图1ANN-SNN转化误差示意图
Fig.1Diagram ofANN-SNN conversion error
图1(b)第1行的例子中,时间步t1,t2达到阈值之后,即刻发放脉冲,之后未达到阈值不发放脉冲,在时间步T累积结束时,总共发放两个脉冲,与SNN期望得到的脉冲个数相比,多发放了两个脉冲. 图1(b)第2 行的例子中,在有限的时间步t5中,膜电位包含的信息足以发放两个脉冲,但实际上只能发放一个脉冲,与SNN期望得到的脉冲个数相比少发放了一个脉冲. 对于基于速率编码的SNN来说,上述情况在极少的时间步下是频繁存在的,其所产生的误差可以在较长的时间步中,通过各个时间步剩余膜电位的叠加来进行缓解,反映在整个时间窗口T上,就是残余膜电位,因此,本文称这种误差为残余膜电位误差RMPE,以期望通过调节与残余膜电位有关的参数来进一步降低误差.
下面,本文从脉冲神经元输入输出发放率之间的关系,分析与残余膜电位误差RMPE有关的参数. 本节假设膜电位残余信息误差产生的误差脉冲数为 M和发放阈值Vth = 1,将式(1)从1累加到T,然后除以T,得到
(5)
(6)
式(5)描述了脉冲神经元输入输出发放率之间的关系,与ANN 前向过程相似. 当模拟时间步 T 足够长时,然而,较高的T会导致较大的推理延迟. 从式(6)中可以看出,由残余膜电位v l(T)产生的残余膜电位误差RMPE与Wl,v l(0)有关,实际上通过调整初始膜电位v l(0)能够调整SNN 输入分布,因此合适的初始膜电位可以使SNN输入分布尽可能满足均匀分布,并且通过调整初始膜电位 v l(0)和权重Wl,可以减少产生的误差脉冲数M,并且将残余膜电位v l(T)限制在后续章节会通过调整这些参数校准转化误差.
3 双阶段训练框架与算法
3.1 本文算法训练框架
基于第3章的分析,为解决对ANN激活值直接进行量化截断导致激活值表示精度不足的问题,本文提出一种双阶段转化方案,如图2所示. 第1阶段,首先,基于ReLU训练源ANN,然后,基于带有可训练阈值的量化截断激活函数训练QC-ANN,实现量化与截断误差的最小化. 第2阶段,首先,将QC-ANN的神经元替换为IF神经元,实现ANN-SNN的转化,此时,需要将网络中BN(batch normalization)层的参数整合到前层中构成预训练SNN,如式(7)所示:
(7)
其中: W,b为前层的权重和偏置参数; γ,σ,β,µ均为 BN层的参数,且γ,β为需要训练的超参数. 然后,通过对SNN的初始膜电位和权重进行逐层校准,以减少残余膜电位误差,得到最终的SNN.

图2双阶段训练算法框架
Fig.2The framework of the two-stage training algorithm
3.2 一阶段训练
3.2.1 量化截断激活函数
依据第3.3.1节IF神经元脉冲响应特性的分析结果(式(3)),对ReLU激活函数进行量化,得到量化截断激活函数如下:
(8)
其中超参数L表示ANN的量化步长,可训练参数λl对应于SNN第l层网络的发放阈值. 采用该激活函数训练得到的 ANN,本文称之为QC-ANN,训练好的 QCANN可转为具有相同权值的SNN.
3.2.2 QC-ANN的训练
本文基于梯度下降法训练 QC-ANN,损失函数 Loss为QC-ANN输出层与训练集标签的交叉熵,即
(9)
其中: y为训练集的one-hot标签, ai为QC-ANN输出层第i个神经元输出的激活值. 为了直接训练量化–截断 ANN,使用直通估计器(straight-through estimator)[21] 对floor函数进行估计,即
(10)
3.2.3 IF神经元与QC-ANN神经元之间的误差
假设根据式(3)和式(8),可得到IF神经元的输出与QC-ANN神经元的输出之间的误差如下:
(11)
在训练QC-ANN时,对SNN的各层阈值进行训练,可以使量化截断激活函数的曲线与IF脉冲神经元特性响应曲线尽可能地接近,当二者重叠时,量化误差和截断误之和为最优.
3.3 残余膜电位对应的SNN参数学习与优化
在第1阶段(图2虚线上部)QC-ANN训练结束后,将QC-ANN训练的权重和阈值移植到SNN中,得到不纠正残余膜电位误差RMPE的预训练SNN. 在第2阶段,如图2(虚线下部)所示,采用分层校准算法对初始膜电位v l(0)(layer-wise membrane potential calibration,LMPC)进行逐层校准,并对权重 Wl(layer-wise weights calibration,LWC)进行微调学习,以减少RMPE.
3.3.1 初始膜电位逐层校准
初始膜电位的设置,不仅可以用于将残余膜电位控制在范围之内,还可以用于调整脉冲序列的分布,使其尽可能接近理想的均匀分布. 为了拟合量化截断ANN的激活值考虑使用N个样本来校准初始膜电位,在不考虑误差脉冲数的前提下,依据式(6)可以推导出SNN理想激活值与发放率之间的误差函数,如下:
(12)
在理想状态下,可以令式(12)等于0,从而显式推导出初始膜电位的表示式,如下:
(13)
依据式(13),可以利用SNN理想输出激活值与 QCANN实际激活值之间的误差校准初始膜电位. 至此,即可利用脉冲神经元膜电位在整个时间窗T内(理想的SNN输出激活值)的增量来校准初始膜电位,控制残余膜电位信息的范围和调整输入脉冲序列的分布,减少残余膜电位误差RMPE.
3.3.2 权重微调学习
为了更精确的纠正残余膜电位误差RMPE,本文利用目标激活值a l与真实脉冲发放率r l的最小均方误差,来校准不同时间步T 下的权值. 这里采用与Li和 Deng等人 [16-17] 类似的分层优化方法进行权重的微调学习,即
(14)
真实脉冲发放率rl需要在时间步T上进行累积,由于脉冲发放函数是不可微的,为了解决脉冲函数不可微问题,本文采用代理梯度f(v)[22] 替代和脉冲表示 [23] 进行时间反向传播(back-propagation through time,BPTT)算法,即
(15)
其中γ是一个常数,表示梯度的最大值,然后用BPTT得到的权值的梯度为
(16)
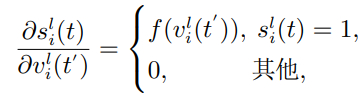
(17)
为了使用较低的成本进行微调,采用小批量样本(mini-batch)mini-batch=1024,在SNN层面,通过利用随机梯度下降算法微调(fine-tuning)权重来减少残余膜电位误差(RMPE). 基于上述校准算法,可以实现在极少时间步(T = 4)下的高精度ANN-SNN转化.
4 实验
4.1 数据集及相关实验设置
本文训练VGG-16和ResNet-20 [24] 作为基准 ANN 模型,再将其转化为 SNN,并在 CIFAR-10和CIFAR100数据集上验证本文所提出的方法. 本文使用动量参数为0.9的随机梯度下降优化器,余弦衰减调度器来调整学习速率. 第1阶段: ANN的两次训练: 基于ReLU训练的源ANN的学习率设置为0.1; QC-ANN的学习率设置为1e-5; 第2阶段: 初始膜电位校准和基于 BPTT的SNN的微调训练阶段,在CIFAR-10,CIFAR100数据集上初始学习率分别设置为1e-4和1e-5. 对于第1层的输入,本文采用文献 [16] 中的方法,将归一化后的像素值直接编码为脉冲序列. 本文经过不同的 L对应的QC-ANN,Phase I和Phase I4+Phase II不同阶段训练进行研究,发现当量化步长L = 4时,QC-ANN 的最终精度较低. 当L >4时,训练得到的QC-ANN 精度趋于稳定. 极低延迟下 SNN的精度随着L的增加而降低,但是过小的L会限制QC-ANN及其转换得到的SNN的最高精度. 不同的L对应不同的QC-ANN的精度、量化误差和截断误差,会影响Phase II校准算法提升精度的幅度. 因此,本文选取了一个折中的值,即将L设置为8. 本文实验基于Pytorch 深度学习框架实现,硬件平台: CPU: Intel Xeon E5-2698 v4 2.2 GHz,GPU: Tesla V100.
4.2 消融实验
本文利用VGG-16和ResNet-20网络结构在CIFAR-10和CIFAR-100数据集上训练的ANN精度分别为 95.71%,95.23%和77.10%,75.07%,将第1阶段量化截断表示为 Phase I,第2阶段完整校准算法为 Phase II,根据实验结果,在VGG-16和ResNet-20 网络结构上,基于本文方法将ANN转化为SNN后的分类精度分别为95.75%,95.23% 和77.10%,76.38%. 在这里,本文进行消融实验来验证Phase I的量化和Phase II校准方法的有效性. 在4种条件下,分别在CIFAR-10 和CIFAR-100数据集上,从T = 2到T = 64,测试VGG-16和 ResNet-20网络结构在Phase I(量化)、逐层膜电位校准(layer-by-layer calibration of initial membrane potential,LMPC)、逐层权重微调(layer-by-layer weight calibration,LWC)、Phase I+Phase II下的精度.
为了验证第1阶段QC-ANN阈值训练的效果,本文将阈值训练的结果与 Max Norm 和Robust Norm 等阈值设置方法的结果进行了比较,如表1所示. 从表1可以看出,本文的阈值优化方法优于现有的常用阈值优化方法.
进一步验证第2阶段校准方法的有效性,如图3所示,Phase I(量化)在取得的转化效果最差,因为 QC-ANN只简单的平衡了截断误差(CE)和量化误差(QE),而忽略了在极低延迟下的残余膜电位误差导致的损失. 在Phase II中的两种不同的校准方法LMPC 和LWC,对于转化精度都有一定程度的提升,说明在很好平衡了截断误差(CE)和量化误差(QE)的情况下,减少了残余膜电位误差RMPE. 在VGG-16网络结构中,LWC校准方法在时,得到的结果比LMPC校准方法的精度更好. 在ResNet-20网络结构中,LWC 校准和LMPC校准得到的精度相差不大,说明通过校准初始膜电位也能达到LWC校准的精度. 图3Phase I+Phase II曲线显示,Phase I+Phase II在所有时间步中均能取得最佳的精度,说明在平衡了截断误差(CE)和量化(QE)误差的前提下,极大的减少了残余膜电位误差RMPE.
表1不同阈值设置方法在不同的模拟时间步长下得到的SNN Top-1精度比较
Table1Comparison of SNN Top-1 accuracy obtained by different threshold setting methods under different simulation time steps

根据已有的研究 [16,19],如果在时间窗口T结束时,残余膜电位表示在时间窗口T内没有信息残留. 为了更显式的说明校准RMPE的效果,本文统计在时间窗口T结束时,每一层神经元残余膜电位的神经元数量,如图4–5所示,VGG-16在CIFAR数据集上,通过不同校准算法之后得到的SNN具有RMPE神经元的比例在Phase I的基础上有所减少,说明了第2阶段校准算法的有效性.
本文在CIFAR-100数据集上验证逐层校准初始膜电位与已有校准方法的对比,如表2所示,本文的初始膜电位校准方法与已有的方法在不同时间步下的精度比较. 与统一设置初始膜电位为的OpI [18] 方法和每个时间步分配偏移量Opt [17] 方法相比,使用本文提出的LMPC膜电位校准方法在低延迟下得到的精度更高,例如,在转化VGG-16网络结构时,本文的初始膜电位校准方法只需要16个时间步就可以获得74.48%的精度.


图3基于 CIFAR-10 和 CIFAR-100 数据集,在不同时间步下的SNN消融实验精度曲线
Fig.3Based on CIFAR-10 and CIFAR-100 datasets, experimental accuracy curves of SNN ablation at different time steps were obtained
4.3 与其它研究工作的对比
在本节中,为了进一步说明本文工作的有效性,这里使用VGG-16和ResNet-20网络结构在CIFAR-10和 CIFAR-100数据集上进行实验,并将 Top-1的精确度与一些最佳模型进行比较. 如表3所示,与RateNorm [15] 调整阈值的缩放因子相比,RateNorm [15] 减少前文分析的截断误差而忽略量化误差,因为截断误差与量化误差之间存在平衡关系,仅仅减少截断误差会导致量化误差的增加. 本文在ANN中进行可训练阈值,实现了截断误差和量化误差的最优平衡. 膜电位阈值优化(optimized potential threshold,Opt)[17]、初始膜电位优比(optimized potential initialization,Opl)[18] 假设 SNN输入满足均匀分布逐层分析误差,将初始膜电位设置为理论最优值,但SNN输入分布会在不同数据集上有所差异,导致固定设置的初始膜电位在深层次网络中不一定达到最优的结果,本文利用SNN脉冲神经元实际输入的增量得到的发放率与源ANN激活值之间的差异进行逐层校准初始膜电位,相较于固定设置的初始膜电位更加精确. 文献 [16] 利用SNN模拟输出发放率与源ANN激活值直接的误差进行校准,因为模拟发放率需要在时间步非常长的时候才能达到与实际发放率相似的输出,导致在极低延迟下的精度很低,本文从脉冲神经元异步传输特性分析残余膜电位不一定满足[0,Vth),并且利用BPTT算法,在极低延迟下利用实际发放率与源ANN激活值之间的均方误差来校准误差. 量化剪辑激活函数(quantization clip floorshift,QCFS)[19] 将集成–发放(IF)神经元脉冲响应特性得到的量化截断移位激活函数作为源ANN的激活函数,在实验中发现,对于量化截断移位激活函数训练得到的ANN精度波动较大,针对这个问题,本文提出在双阶段训练框架中对ANN进行二次训练算法,并且QCFS [19] 将残余膜电位限制为[0,Vth),从而忽略了由于脉冲神经元异步传输特性产生的残余膜电位信息误差,导致在低延迟下精度有所损失,本文从脉冲神经元输入输出发放率之间的关系分析出与残余膜电位信息误差有关的参数,并且提出一套逐层校准算法. 在极低推理延迟T = 4时,在CIFAR-10上训练的 VGG-16和ResNet-20 精度分别可达93.28%,85.43%,在CIFAR-100上训练的 VGG-16和ResNet-20 精度分别可达67.69%,50.41%. 为了证明本文模型不需要过多的推理延迟(T≤ 128),表3还列出了不同时间步长的推理准确率,并与其他工作进行了比较,结果表明,本文的方法优于以往的转化方法.

图4CIFAR-10上不同校准算法对应的Spiking VGG16具有的RMPE的比例
Fig.4The ratio of RMPE in VGG-16 obtained by different calibration algorithms on CIFAR-10

图5CIFAR-100上不同校准算法对应的Spiking VGG-16具有的RMPE的比例
Fig.5The ratio of RMPE in VGG-16 obtained by different calibration algorithms on CIFAR-100
表2不同初始膜电位校准方法,在不同的模拟时间步下的SNN Top-1精度
Table2Accuracy under different simulation time steps

4.4 能耗估计
本文对VGG-16网络结构在CIFAR-100数据集上的发放率进行了统计,时间步T = 64时的平均发放率为0.0616,这反映了脉冲活动的稀疏性. 本文采用已有工作 [25] 中的能量估计方程进行能耗估计. 本文SNN 与ANN能耗之比为
(18)
其中: α表示乘法的能量消耗4.6 pJ [26]; β表示加法的能量消耗0.9 pJ [26]; a,b,c 分别表示 ANN,SNN和SNN第1 层的操作次数. 根据式(18),计算出当T = 64 时,本文提出的模型计算能耗,只需要 ANN能耗的 70.06%.
5 总结
针对基于速率编码的SNN推理延迟大、输入符合均匀分布这一简单假设、直接采用量化截断移位激活函数替换ReLU函数进行ANN训练精度波动大等问题,本文提出了一种ANN-SNN双阶段转化框架与算法,实现了超低延迟的深度SNN. 本文首先分析了极低延迟下SNN精度损失的主要原因,提出残余膜电位误差RMPE的概念,并对其进行分析与推导,建立残余膜电位与初始膜电位和权重之间的关系模型. 然后,基于所建立的残余膜电位模型,提出一种初始膜电位和权重的分层校准算法,减少残余膜电位误差,从而解决脉冲输入序列均匀分布假设与真实分布不一致的问题. 最后,提出一种ANN-SNN的双阶段转化框架,以实现量化误差与截断误差的最优化,使得在极低延迟下的ANN-SNN转化也能获得较高的精度. 实验结果表明,本文方法所构建的SNN在分类精度、推理延迟性能指标上均获得了最好的结果.
表3与其他已有的SNN转化算法的比较.
Table3Comparison with other existing SNN conversion algorithms

*: 量化步长L = 8.