摘要
宽度学习系统(Broad Learning System, BLS) 及其改进算法均普遍存在一个问题, 即随着实际场景中数据复杂性的逐步增强, 网络结构变得极其复杂, 进一步导致计算资源的消耗也大幅度增加. 针对此问题, 本文提出了一种带有Dropout算法的贝叶斯近似宽度学习系统(Dropout-BABLS). 首先, 利用Dropout算法对宽度学习系统的隐藏层节点随机进行丢弃. 其次, 通过结合高斯回归过程和贝叶斯理论近似Dropout对输出结果的损失函数以确定Dropout-BABLS的目标函数, 进一步采用增广拉格朗日乘子法对目标函数的输出权重进行优化求解. 最后, 通过UCI机器学习知识库的10组回归数据集和自建的6组时间序列数据集对算法进行分析评估. 结果表明, 本文所提出的Dropout-BABLS算法能保证相应的输出精度, 并减少25% ∼ 50%的运行时间.
Abstract
The existing broad learning system (BLS) and its improved algorithms have a common problem, that is, with the increasing complexity of data in practical scenarios, the network structure becomes extremely complex, resulting in the consumption of computing resources increased greatly. To handle the problem, this paper proposes a Bayesian approximate broad learning system with dropout structure (Dropout-BABLS). Firstly, the dropout algorithm is used to randomly discard the hidden layer nodes of Broad Learning System. Secondly, by combining the Gaussian regression process and Bayesian theory to approximate the loss function of Dropout on the output results, the objective function of Dropout-BABLS is determined. Next, the augmented Lagrange multiplier method is used to optimize the output weight of the objective function. Finally, the analysis and evaluation of the algorithm 10 sets of regression data of UCI machine learning knowledge base and 6 sets of time series data builted by ourselves. The results show that the developed algorithm by Dropout-BABLS can maintain the corresponding output accuracy and reduce the training time by 25% to 50%.
1 引言
随着人工智能技术的飞速发展,深度神经网络已经成为人工智能领域最热门的研究方向之一,在计算机视觉、自然语言处理、机器人技术等一系列具有挑战性的领域取得重大创新和广泛应用 [1] . 深度神经网络通过不断增加网络层数来提升网络的泛化能力,具有优秀的特征提取能力和良好的非线性逼近能力 [2] . 它是在反向传播过程中采用逐层求梯度的方式更新网络的权重,这使得深度神经网络模型容易陷入局部最优解、训练时间长等问题. 针对此问题,Chen等人 [3] 于2018年提出了宽度学习系统(Broad Learning System,BLS)并证明了其良好的性能 [4] . 相较于深度神经网络,BLS具有网络结构简单、参数少等优点,能够有效减少训练时间和节约计算资源.
近年来,宽度学习得到了国内外诸多学者的关注. Jin等人 [5] 提出了一种基于L1范数和L2范数正则化方法的鲁棒性宽度学习系统,有效减少了BLS隐藏层节点的冗余,提高了算法的鲁棒性,但该方法最主要是为提升算法的鲁棒性,对BLS结构的精简程度仍稍显不足. 为进一步精简BLS的网络结构,褚菲等人 [6] 提出了一种基于lasso和elastic net的宽度学习系统,并证明了其在网络稀疏上的可应用性. 考虑到BLS的随机映射对输出结果的影响,Wang等人 [7] 通过改变BLS模型的初始随机映射权重分配方法提出了GBLS,进一步提高了模型的数据处理能力,但仍对数据的特征提取程度不够. Cao等人 [8] 提出了一种带有混合特征的BLSHF算法,用不同的分布来初始化每个组中的映射特征节点,从而增加映射特征的多样性,可以实现比BLS更好的泛化能力,但也带来了冗余特征. 相较于只向“宽度”方向构造的改进宽度学习系统,其 “深层”结构有助于提高BLS的精确性. Liu等人 [9] 为解决BLS的浅层结构对于其算法能力的限制,提出了一种具有动态结构的堆叠宽度学习系统Stacked BLS. Zhang等人 [10] 深入分析了BLS快速增量学习的原理,根据深度神经网络的新结构设计理念在级联结构的基础上分别结合金字塔结构、Dropout操作和密集结构提出了四种全新的BLS变体及其增量实现,有效提高了BLS的输出准确性,但该方法只是“机械”的将级联宽度学习系统与Dropout操作结合起来,没有考虑到Dropout算法对节点丢弃后对输出精度的影响.
综合上述分析,为进一步解决宽度学习系统在面对真实场景应用下的复杂数据时容易出现网络结构过于复杂而导致模型训练成本增加的问题,本文提出了一种带有Dropout结构的贝叶斯近似宽度学习系统(Dropout-BABLS). 该方法考虑了Dropout算法以概率p 对BLS的隐藏层节点随机屏蔽时造成模型输出精度下降的情况,通过引入损失函数对Dropout-BABLS 目标函数进行逼近. 通过结合高斯回归过程和贝叶斯理论对Dropout-BABLS的目标函数进行近似,进一步采用增广拉格朗日乘子法来对目标函数进行优化改写,然后利用块坐标下降法求解出模型的输出权重. 最后,分别结合10组回归数据集和6组真实应用场景下的复杂数据进行实证分析,进一步为BLS的应用与相关算法的改进提供一定的思路和理论支撑.
2 宽度学习系统
对于输入维度为C,输出维度为1的单输出回归训练数据集,其中,i = 1,2,· · ·,N. 首先,将输入数据X随机映射到n个特征节点组,每个特征节点组包含k个特征节点,第i个特征映射组可以表示为:
(1)
其中,Wei,βei是网络随机生成的第i个特征节点组的权重和偏置,ϕ (·)是特征映射函数. 定义训练数据集的特征节点空间为Z n = [Z1,Z2,· · ·,Zn],然后以Z n作为输入通过非线性变换生成m个增强节点组,每个增强节点组包含q个特征节点,第j个增强节点组的输出定义为:
(2)
其中,Whj,βhj是网络随机生成的第j个增强节点组的权重和偏置,ξ (·)= tanh(·)是非线性激活函数. 定义增强节点空间的输出为Hm= [H1,H2,· · ·,Hm],最后将所有特征节点组和增强节点组串联起来作为BLS 的隐藏层,因此,宽度学习系统的输出为:
(3)
其中,A = [Z n |Hm ]为BLS隐藏层的串联节点空间, W是连接隐藏层到输出层的输出权重. 一般来说,A 是奇异的,甚至可能为病态矩阵 [5],因此,输出权重W可通过下式最小化目标函数优化求解:
(4)
其中,λ是正则化参数,式(4)中第一项用以控制模型训练误差最小化,第二项用以防止BLS模型过拟合. 通过岭回归方法 [11],对式(4)关于W求导并置导函数为0,求解得到:
(5)
训练结束后,随机生成的权重Wei,Whj和训练得到的输出权重是固定的W. 因此,BLS对样本量为M 的测试数据集的响应为
(6)
其中,At是宽度学习系统对输入数据Xt生成的隐藏层.
3 基于Dropout的贝叶斯近似宽度学习系统
3.1 Dropout-BABLS结构
Dropout是Hinton等人 [12-13] 提出的用于解决神经网络出现过拟合现象的方法,能够适用于宽度学习系统出现网络结构复杂、隐藏层节点数量较多的情况. Dropout在对宽度学习系统进行训练时,对节点组的激活值随机置为0或1,激活值为0的节点组不参与输出BLS的结果,其中,激活值的随机选取服从以概率p为参数的伯努利分布 [14] . 本文将带有Dropout结构的的宽度学习系统记为Dropout-BABLS,其网络结构如图1所示.

图1Dropout-BABLS的网络结构
Fig.1Network structure of Dropout-BABLS
记rk为A中第k个节点组的激活值依概率p被置为0或1,k = 1,2,· · ·,n + m. 则由以下过程得到Dropout层输出 为:
(7)
其中,◦代表哈达玛积 [15] . 此时,宽度学习系统的输出变为
(8)
(9)
其中,γ是权重衰减因子.
3.2 基于Dropout的贝叶斯近似
不同于传统的BLS采用岭回归的方法直接求解输出权重W,本节通过高斯回归过程 [18],将统计学中的概率论方法与Dropout-BABLS结合起来,引入贝叶斯理论优化Dropout-BABLS的目标函数,再利用增广拉格朗日乘子法对目标函数优化求解.
根据贝叶斯定理,对于BLS随机生成的隐藏层A,模型参数W的后验分布可以表示为:
(10)
(11)
(12)
其中,wk ∼ p(W),τ为模型精度的超参数,本文将其值设置为0.9. IN为N × N维的单位矩阵. 基于高斯过程,可以得到预测分布为
(13)
对F进行解析积分,得到:
(14)
令为1 × K维行向量,有N × K维特征矩阵易得K (A,A)= ΦTΦ,则式(14)可以重写为:
(15)
根据式(13)-(15),易得:
(16)
通过以上分析,宽度学习系统对新的输入x ∗的预测分布可以参数化为
(17)
式(17)中,a∗是输入x ∗生成的新的BLS隐藏层,后验分布是难以解析求解的,需要通过变分推断的方法引入一个变分分布q(W,):=q(W)q()来近似p(W,|A,Y). 通过最小化变分分布q (W,)与后验分布p (W,|A,Y)的 Kullback–Leibler(KL)散度,来确定最优变分分布近似实际的后验分布,KL散度计算如下:
(18)
对于式(18)中等式右边第二项,有
(19)
由于p(Y |A)是一个常数,依照式(18)和式(19),可知最小化KL散度等价于最大化对数证据下界(the Log Evidence Lower Bound,ELBO),即
(20)
利用蒙特卡洛积分进行对式(20)进行近似. 首先从q (W,)采样 和,然后针对q(W,)进行优化,以最大化式(21)的目标函数. 接下来,更新q (W,),并从中抽取新的样本 和和. 重复上述操作,最终收敛到一个最接近真实后验分布p(W,|A,Y)的q(W,).
(21)
在宽度学习系统的隐藏层与输出层之间添加一个Dropout层,取W ∼ p(W),构造q(W)如下:
(22)
其中,隐藏层节点组失活概率p与矩阵 为变分参数. 变分分布q(W)是高度多模态的,在 的行上诱导强联合相关性. 关于随机误差的变分分布q(),可以取一个简单的高斯分布:
(23)
对于回归任务,由式(16)可以将式(20)中右边第一项的被积函数重写为:
(24)
高斯过程的各输出是独立的,忽略系统随机生成的误差,有Φ ≈ = AW. 于是,式(24)可以转化为:
(25)
根据文献 [25] 的研究理论,q(W,)和p(W,)之间的KL散度可以近似为:
(26)
通过上述分析,式(20)可转化为最小化下式的目标函数:
(27)
其中,E ( Y,)满足下式:
(28)
至此,从数学理论的角度证明了,最小化带有Dropout结构的宽度学习系统的目标函数,同最小化变分分布与高斯过程的后验分布之间的KL散度所达到的优化效果一致,即LGP−MC等价于LDropout.
3.3 Dropout-BABLS优化求解
由于Dropout-BABLS的目标函数LGP−MC结构较为复杂,不易通过解析求解出权重W. 本节利用增广拉格朗日乘子法(the Augmented Lagrange Multiplier,ALM)来对目标函数LGP−MC进行优化求解,引入松弛变量D来替代AW,同时由e = Y − AW,可将式(27)改写为:
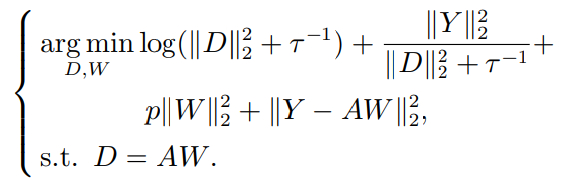
(29)
依据ALM方法,式(29)的增广拉格朗日函数为
(30)
其中, C为拉格朗日乘子,µ ≥ 0是惩罚因子. 然后,利用块坐标下降法优化求解上式中的未知变量D,W,C,具体步骤如下:
1)求解W: 令保持变量D,C不变,移除与W无关的项,可得下式:
(31)
上式是一个典型的正则化最小二乘问题,其解为
(32)
2)求解D: 令保持变量W,C不变,移除与D无关的项,可得下式:
(33)
由式(33)可知,D满足下式:
(34)
3)拉格朗日乘子C迭代: 在每次迭代中,参数C可以更新为:
(35)
对于给定的拉格朗日乘子C和惩罚因子µ,通过迭代重复块坐标下降(32)、(34)所生成的递归序列 { Dl,Wl } 最终会收敛于式(29)的最优解,这是容易证明的,本文不再对此重复赘述 [24-25] .
4 实验与分析
4.1 实验设计
为了验证Dropout-BABLS算法的有效性,本文选取传统机器学习算法(SVM和LSSVM)、神经网络领域前沿算法(自适应深度神经网络ADNN [25]、非线性自回归神经网络NARNN [26] 和单层长短时神经网络LSTM [27])、标准BLS、L1BLS、ENBLS、L1RBLS、ENRBLS和DKBLS [28] 进行对比实验,每组实验均进行20次独立实验并选取最优实验结果进行比较分析,以平均绝对百分比误差(MAPE)和均方根误差(RMSE)作为算法测试精度的评价指标.
算法的参数选取对学习效果具有重要的影响作用. 因此,为了公平的比较本文所提出的Dropout-BABLS 算法与其他算法的回归效果,需要通过合适的方式进行参数设置. 对于SVM算法,采用网格搜索法从[2−24,· · ·,2 25]来确定不同数据集的惩罚参数C和径向基函数核参数γ,LSSVM则通过MATLAB工具箱LSSVM-lab来确定(C,γ). 就本文而言,3种神经网络前沿算法的输入层节点数l与输入变量数一致,输出层节点数为1. 其中,采用顺序搜索法来对自适应深度神经网络 ADNN的隐层数h和各隐层节点数q进行搜索,搜索范围分别为[1,5]和[1,l]; 非线性自回归神经网络NARNN的延迟阶数k根据数据集特点分别设置为2或3 [26],其隐层节点数q则根据经验公式
采用顺序搜索的方法进行选取; LSTM的隐层节点数则利用网格搜索法从[1,100]范围内以步长1进行搜索确定. 同时,还需要对 Dropout-BABLS,标准 BLS,L1BLS,ENBLS,L1RBLS和ENRBLS进行网格搜索,包括每个特征节点组中的特征节点数量k、特征节点组数量n和每个增强节点组中的特征节点数量q,分别针对不同回归数据集从[1,20]×[1,20]×[1,200]中搜索,步长设置为1. 另外,将Dropout-BABLS的隐藏层失活概率p和模型精度τ设为0.5和0.9. 对于DKBLS,只需对高斯核函数参数 σ 进行调节即可,本文采用顺序搜索法从[2 -10,2-9,· · ·,2 9,2 10] 范围内选取σ. 所有实验均采用统一的实验平台. 具体配置信息为: CPU为AMD Ryzen5 5500U@2.10 GHz 6Cores,内存16 GB,图像处理单元(GPU)为AMD Radeon(TM)Graphics,操作系统为Windows11终端,其中Friedman post-hoc test 检验实验的编程语言及版本为 R语言 4.2.3版本,其他所有实验的编程语言及版本均为MATLAB2022b.
4.2 回归数据集测试
4.2.1 数据集描述
表1回归数据集的规格信息
Table1Specification information of regression data set

4.2.2 不同算法实验结果分析
对每个算法的参数依照上述实验设计进行选取,结果如表2所示. 通过观察表2,可以发现本文所提出的Dropout-BABLS算法相较于BLS、L1BLS、ENBLS、L1RBLS和ENBLS,所需的隐藏层节点数量更多. 这是因为Dropout-BABLS对隐藏层节点进行了随机丢弃,需要增加更多的节点以保证模型输出结果的精确度.
在选定所需的参数之后,得到每个算法的回归测试结果见表3. 从算法的训练时间来看,Dropout-BABLS在网络节点数量增加的情况下所需要的学习时长明显优于其他BLS改进算法,相较于ADNN、NARNN和单层LSTM这三种神经网络前沿算法而言,Dropout-BABLS具有更高效的学习能力. 从算法测试时间来看,Dropout-BABLS 算法除了对Weather Izmir的测试集进行测试所需的时间略高于ENBLS算法外,对其他9组回归数据集进行测试所需的时间均明显低于其他算法. 从算法的输出结果来看,Dropout-BABLS对于10组回归数据集输出结果明显优于标准BLS算法和传统机器学习算法SVM与LSSVM; 同时,相较于其他宽度学习系统的改进算法以及三种神经网络前沿算法,Dropout-BABLS的输出精度得到了明显地提高. Dropout-BABLS在Abalone和Quake两个数据集上取得了显著优势,不仅训练成本也大幅降低,其输出精度得到了略微提升. 此外,Dropout-BABLS在Bodyfat、Strike、Basketball、Cleveland和Pyrim这5个数据集上也取得了相对比较明显的优势. 特别地,通过表3可以发现,Dropout算法对数据集Housing的影响相对较大的,但通过本文提出的贝叶斯近似方法对BLS进行优化后,Dropout-BABLS与ENBLS 在Housing数据集上输出精度MAPE和RMSE的差异也分别仅为1‰和4‰.
表2各算法的参数设置
Table2Parameter setting of each algorithm

为了进一步比较Dropout-BABLS相较于其他算法的优越性,本节对各算法的训练时间进行了Friedman post-hoc test检验,结果如表4所示. 结果表明,相较于传统机器学习算法和神经网络前沿算法,Dropout-BABLS 在显著性水平0.01条件下具有显著差异,可以认为Dropout-BABLS在节约训练成本上具有显著优势. 对于BLS及DKBLS两个算法来说,Dropout-BABLS也能在0.01水平条件下通过显著性检验,说明Dropout-BABLS能极大程度减少宽度学习系统的隐层节点数量而不降低模型的输出精度. 对于L1BLS、ENBLS、L1RBLS和ENRBLS 来说,Dropout-BABLS仅能在显著性水平0.05条件下通过检验,这是由于这四种算法的目标函数均包含L1范数,能够一定程度上稀疏BLS的网络结构,但简化程度相较于Dropout-BABLS而言仍有较大差距.
4.3 时序数据预测
4.3.1 数据集构造
为了验证Dropout-BABLS对现实数据的学习能力,本节利用天气后报网(http ://www .aqistudy .cn/historydata/)提供的空气质量历史数据,采集了山东省青岛市、济南市、烟台市、聊城市、临沂市和日照市等6个城市2022年01月01日-2022年10月31 日的历史空气质量数据,分别包含PM2.5、AQI、 PM10、NO2、SO2、CO和O3等7个变量,其中,PM2.5与其他6个变量具有高度相关性 [30] . 为了消除各变量不同量级、量纲的影响,需要分别依照式(36)对获取到的原始数据进行标准化处理. 在得到标准化数据之后,以AQI、PM10、NO2、SO2、CO和O3作为输入变量X,PM2.5作为输出变量Y,将2022年01月01日-2022年08月31日的标准化数据作为训练集、2022年09月01日-2022年10月31 日的标准化数据作为测试集,自建了6组时间序列数据集用于本节的实验测试与分析.
式中: X′为标准化数据,X为原始数据,Xmin和Xmax 分别为数据的最小值和最大值.
(36)
4.3.2 预测结果比较与分析
利用各算法对6个城市2022年09月01日–2022年 10月31日的PM2.5进行预测,发现Dropout-BABLS对烟台市、济南市和聊城市3个城市的PM2.5预测效果相对较好,MAPE值分别为4.3%,4.14%和4%. 本文所提出的Dropout-BABLS算法对烟台市、聊城市、临沂市和日照市的预测效果均明显优于其他改进BLS算法和3种神经网络前沿算法,对青岛市的预测效果仅次于ENBLS,对济南市的预测效果仅次于ENRBLS算法,整体预测精确度都相对较高. 在青岛市预测任务中,Dropout-BABLS与ENBLS的MPAE和RMSE仅相差0.69%和0.37%,但Dropout-BABLS 的训练和测试时间相较ENBLS 减少了一半以上,进一步体现了 Dropout-BABLS算法的性能优势. 从各算法执行所需时间来看,单层 LSTM需要的时间相对优于除 Dropout-BABLS外的改进BLS算法,其输出精度也略差于其他算法. ADNN和NARNN对6组时间序列数据的预测效果和其他BLS改进算法没有明显的差异,而 Dropout-BABLS在一定程度上提高算法预测精度的同时大幅度节省了算法训练的时间. 具体如表5所示.
表3各算法的输出结果
Table3Output results of each algorithm

表4Dropout-BABLS与其他算法的Friedman post-hoc test检验结果
Table4Friedman post-hoc test results for Dropout-BABLS and other algorithms

5 总结
为有效解决宽度学习系统在面对真实场景下时网络结构过于庞大导致计算资源损耗增加问题,本文提出了一种带有Dropout结构的贝叶斯近似宽度学习系统(Dropout-BABLS)。通过对10组回归数据集和6组时间序列数据集进实证分析. 结果表明,本文所提出的算法在保证输出精度的条件下显著提高了算法的学习能力,减少了计算资源的消耗,同时,Dropout-BABLS对真实场景下的时序数据预测效果也取得了良好的效果. 本研究仅针对回归和预测问题进行了基于Dropout 的贝叶斯近似,后续研究将把Dropout-BABLS 扩展到模式识别分类领域,提升算法的普适性和可移植性.
表5时序数据预测效果对比
Table5Comparison of prediction effects of time series data
