摘要
由于零部件之间复杂的关联关系, 产品设计变更效应的传播在所难免. 为降低产品设计变更带来的风险, 以变更对产品综合性能影响、变更经济成本和变更工期作为优化目标, 本文提出了一种强化学习引导的产品变更路径多目标差分进化算法. 首先, 建立问题的复杂产品网络模型, 揭示产品零件变更的传播机制; 接着, 引入变更传播强度, 间接评价零件变更对产品综合性能的影响; 同时, 考虑变更经济成本和变更工期指标, 建立产品设计变更传播路径的多目标优化模型; 进一步, 利用双深度Q-网络帮助种群在不同阶段选择适合的进化策略, 提出一种强化学习引导的差分进化算法, 简称为DDQN-DE, 并通过上述算法求解最佳的产品设计变更传播路径. 最后, 以创维公司某型号电视机的设计变更问题为例, 并与已有算法进行对比, 实验验证了所提算法的有效性.
Abstract
Due to the complex interrelationships between components, the propagation of product design change effect is inevitable. To reduce the risk associated with product design changes, this paper proposes a multi-objective differential evolution algorithm guided by reinforcement learning to optimize the impact of changes on the product performance, economic cost, and change duration. Firstly, a complex product network model is established to reveal the propagation mechanism of component changes. Then, the change propagation intensity is introduced to indirectly evaluate the impact of component changes on the product performance. Meanwhile, considering the economic cost and change duration of design changes, a multi-objective model for optimizing design change propagation paths is established. Furthermore, utilizing dual deep Q-networks to assist populations in selecting appropriate evolutionary strategies at different stages, introducing a reinforcement learning-guided differential evolution algorithm, abbreviated as DDQN-DE, and using the above-mentioned algorithm to determine the optimal propagation path for product design changes. Finally, taking the design change problem of a TV product from skyworth company as an example and comparing with existing algorithms, the validity of the proposed algorithm is verified through experiments.
1 引言
设计变更在复杂产品研发过程中不可避免 [1] . 由于客户需求、供应链中断、法律法规变化等原因,现实生产经常需要重新设计整个产品或其关键零部件 [2] .由于产品零部件之间复杂的关联关系,一个零部件的设计变更可能导致其他零部件发生连锁变更,从而引发变更传播 [3] . 如果不能有效控制产品设计变更传播,势必对产品综合性能、成本和研发工期产生负面影响 [4] . 因此,研究变更传播路径优化问题,可以帮助决策者选择最佳的变更方案,减小零部件变更对产品综合性能、成本和研发工期等的负面影响.
研究控制产品设计问题时,首先需要建立一个合理的产品零件关联模型. Yang等 [5] 使用设计结构矩阵(design structure matrix,DSM)定量表示产品组件间的关联关系,完成了产品零部件关系的可视化. 针对DSM仅适用于某些特定产品实例的缺点,Diagne 等 [6] 提出了扩展概念设计语义矩阵,可以为DSM提供额外的信息. 李玉鹏等 [7] 充分考虑产品变更时零部件的变更传播流向,构建了面向复杂产品网络结构的有向加权网络. 这些工作为有效分析产品变更传播机制奠定了良好的基础,但是,他们都未考虑与用户体验相关的产品综合性能指标,使得构建的复杂产品网络模型难以满足实际需求.
在建立产品零件关联模型后,需要定义一个合适的指标来评估设计变更对产品综合性能的影响. Dong等 [8] 根据网络变更率、变更放大率和变更放大节点率指标,定义了一种基于变更工作量的综合评价指标. 该指标独立于专家经验,为产品设计变更问题提供了一种更为清晰和客观的变更影响评估方法. Ma 等 [9] 同时考虑变更传播概率、设计裕度、节点度和长程连接信息,定义了一种综合评价指标,用于评估产品变更传播强度(change propagation intensity,CPI). 上述指标可以从不同角度评价设计变更对产品网络模型的影响,然而,由于已有复杂产品网络模型的自身局限性,这些指标并不能反映产品设计变更对综合性能的影响. 因此,目前针对零件变更对产品综合性能影响的揭示和量化研究成果仍较少.
此外,为了有效控制产品变更传播的范围,还需要寻找最优的产品设计变更传播路径. 少数学者尝试将具有全局搜索能力的进化算法用于搜索最优传播路径. 针对复杂产品设计变更传播路径优化问题,骆建芬等 [10] 建立了设计变更传播路径问题的多目标优化模型,并采用带精英策略的非支配排序遗传算法 II(non-dominated sorting genetic algorithm II,NSGA-II)算法求解上述模型. 针对多源设计变更,为了最小化 CPI、变更风险成本和传播路径长度,Ren等 [11] 建立了设计变更传播路径问题的多目标优化模型,并给出了一种基于NSGA-II的求解算法. 上述算法可以为设计师提供多个变更方案. 然而上述算法还存在以下不足: 一方面,由于复杂产品网络模型自身局限性,算法在寻找最优路径时未考虑变更对产品综合性能的影响; 另一方面,由于采用了传统的多目标进化算法,已有算法依然存在收敛速度慢、易陷入局部最优等缺点.
差分进化(differential evolution,DE)算法是由Storn等 [12] 提出的一种基于种群的进化算法,其具有较强的鲁棒性、搜索能力,且易于实现. 曹蓓等 [13] 设计具有修复功能的参数自适应策略,开发了改进DE算法. Tan等 [14] 通过适应值曲面来指导变异策略的选择,给出了具有自适应变异算子的DE算法. Wu等 [15] 设计修复策略和删除策略,提出了快速有效的改进DE算法. 上述改进的DE算法均提高了算法的竞争力,但是,由于只考虑算法本身,仍然很容易陷入局部最优.
强化学习(reinforcement learning,RL)[16] 是机器学习中的一种著名范式和方法论. DE的进化过程可以看作是一个有限马尔可夫决策过程 [17],其中种群信息相当于环境状态,DE策略相当于动作. 鉴于此,针对多模态多目标优化问题,Li等 [18] 提出了一种基于RL的 DE算法,通过Q-learning算法动态调整群体的进化方向. 针对结构优化问题,Huynh等 [19] 提出了一种基于 RL的参数控制方法,通过Q-learning算法在每次搜索迭代时自适应调整算法的控制参数. 上述方法均通过搜索Q 值表来计算值函数,当状态连续或状态集很大时,查找和存储Q值表代价相对较大. 为此,Tan等 [20] 提出了一种基于深度Q–网络(deep Q-network,DQN)的DEDQN 算法,采用深度RL方法实现进化过程中 DE策略的自适应选择. 然而,DQN通过执行当前时刻最大Q值对应的动作来优化策略,容易过高估计某个动作的价值. 进一步,学者们提出了双深度 Q–网络(double deep Q-network,DDQN)[21],将动作选择和动作价值评估分开,降低了过优估计的风险. 因此,本文利用DDQN来选择种群在不同阶段的变异策略.
针对已有工作的不足和实际需求,研究一种融合 RL和DE的产品设计变更传播路径多目标优选方法. 同时考虑变更传播对产品综合性能影响、变更经济成本和变更工期的最小化,以及问题的约束特性,将复杂产品设计变更传播路径优选问题建模为一个约束多目标优化模型,并设计一种RL引导的DE算法求解该模型. 本文的主要贡献如下:
1)在考虑最小化变更经济成本和变更工期等常用指标的情况下,利用变更传播强度评价变更对产品综合性能的影响; 同时考虑问题的多约束特性,建立产品设计变更传播路径的约束多目标优化模型. 相比已有的优化模型,一方面,产品综合性能评价指标的引入能够确保变更方案的可行性和实用性; 另一方面,在变更传播时,考虑更多的实际约束能够确保变更方案符合实际需求.
2)利用DDQN自主切换不同进化策略,提出一种 RL引导的多目标DE 算法,相比已有产品设计变更传播路径求解算法,一方面该算法具有较强的全局搜索能力,不容易陷入局部最优; 另一方面,由于能够使种群在不同阶段选择适合的进化搜索策略,进一步显著提升种群的寻优能力.
3)定义一种基于超体积测度的奖励函数,相比已有的奖励函数,由于考虑了种群进化的多样性和收敛性,能够获得分布均匀以及收敛的Pareto最优解集.
本文的其余部分安排如下: 第2节介绍复杂产品网络模型和路径优选问题的多目标优化模型; 第3节详细介绍所提算法; 第4节通过对比实验分析验证所提算法的有效性; 最后,第5节对本文进行总结,并展望了未来工作.
2 复杂产品网络模型与问题描述
2.1 复杂产品网络模型
假设某产品由n个零件组成,单个零件使用节点 vi表示,两两零件之间的关联关系和关联强度分别使用边eij和权重wij表示,那么该产品可以表示为复杂网络G =(V,E,W). 其中: V ={vi |i = 1,2,· · ·,n} 表示节点集合,E = {eij |i,j = 1,2,· · ·,n}表示节点间边集合, W = {wij |i,j = 1,2,· · ·,n}表示权重集合. 零件之间的关联强度,在复杂网络模型构建中至关重要. 本节使用区间直觉模糊集(interval-valued intuitionistic fuzzy sets,IVIFS)[22] 确定节点之间的关联强度.
首先,根据表1以及专家经验对节点之间的关联强度进行评估,确定节点之间的综合关联强度区间. 文献 [22] 考虑了节点间的功能联系、节点间的物理结构关系、用户参与程度,以及产品的可持续性和适应性. 类似地,本文也从上述4个方面来计算两个节点之间的关联强度值,具体公式如下:
(1)
式中: 分别为节点之间的物理结构相关强度、功能相关强度; 为设计这些节点时用户的参与程度; 为产品的可持续性和适应性. hs ,hf , hcs和 ha分别为上述4种因素的权重. 以功能相关强度 为例,其相应计算公式 [22] 如下:
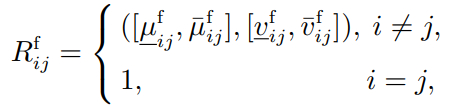
(2)
式中分别表示节点vi和vj的功能相关程度区间和非相关程度区间.
表1相关强度的评估区间
Table1Assessment interval of the relevant intensity

基于上述分析,可以获得不同节点间的关联强度区间,随后采用去模糊化可以得到节点vi和vj间的具体关联强度值wij .
2.2 变更传播模型
为了评估节点变更的传播影响,需要描述节点之间的变更传播机制. 为此,通过引入变更传播概率和设计裕度概念,建立产品设计变更的传播模型.
1)变更传播概率.
变更传播概率Pij表示变更从节点传播到节点的概率 [23] . 具体地,基于产品设计变更数据库,通过计算如下条件概率来获取:
(3)
式中: P(vi)为节点vi发生变更的概率; P(vi ∩ vj)为两个节点同时发生变更的概率.
2)设计裕度.
设计裕度 [24] 是在设计产品时设计者为关键零件留出的设计余量. 当节点vi的设计变更影响cj高于预设的设计裕度∆cj时,需要对此节点进行重新设计.
根据变更传播概率以及设计裕度等概念,可以计算出节点vj的设计变更影响cj ,即
(4)
式中: ci−1,i表示从节点vi的上游节点传播到节点vi时的变更传播影响; 初始变更节点的变更影响c0根据专家经验给出.
2.3 性能指标
2.3.1 变更对产品综合性能的影响
变更传播强度CPI是设计变更传播路径的关键因素 [9] . 本节从变更传播指数、聚集系数和组件重要性方面对CPI进行量化,并通过CPI指标间接描述出变更对产品综合性能的影响.
1)变更传播指数. 变更传播指数可以确定节点的属性 [25],即吸收者/携带者/扩散者. 具体地,变更传播指数Ki的计算公式如下:
(5)
式中: 代表节点vi的出度,即节点vi变更影响到的其他节点的个数; 代表节点vi的入度,即变更会影响到节点vi的其他节点的个数.
2)聚集系数. 聚集系数被用来描述网络中节点之间的整合程度. 在加权网络中,为客观描述节点之间的整合程度需要充分考虑节点之间边的权重值,Onnela等 [26] 将加权聚集系数 定义为
(6)
式中: di表示节点vi的度,即产品网络中与节点vi存在关联关系的节点个数; wij ,wjh和whi分别表示节点vi , vj和vh之间的三边权重,其取值通过等式(1)–(2)计算获得; wmax是产品网络中最大的连边权重值.
3)PageRank(PR)算法. PageRank算法是用来评估网页重要程度的性能指标 [27],它将网页之间的连接视为节点之间的连接. 由于产品零件之间的关系和网页之间的关系存在相似性,因此采用PageRank算法来评估复杂产品网络中节点的重要性. 节点vi的重要性 PRi计算公式如下:
(7)
式中: 节点vj是节点vi的下游节点; DSi是节点vi的下游节点集合; q ∈(0,1)是阻尼因子,一般设置为0.85; n是节点总数.
进一步,借鉴文献 [11] 和文献 [28] 的思想对上述指标进行处理. 首先,根据该指标在整体评价中的相对重要程度为其分配一个权重; 接着,使用线性加权求和法计算这些指标的加权和,进而评估面向多个指标的综合效果. 用于评估一条变更路径(change path,CP)的总变更传播强度CPI值如下:
(8)
式中: w1,w2和w3分别表示变更传播指数、加权聚集系数和组件自身重要性的权重; vi, vj分别表示当前正在变更的节点和下一个需要变更的节点; CP = {cp0,cp1,· · ·,cpi−1,cpi,cpi+1,· · ·,cpm|m <n}表示一条变更传播路径. 其中: cp0表示初始变更节点; cpm表示路径的终止节点.
2.3.2 变更经济成本和变更工期
设计变更不仅会增加产品设计的经济成本,而且会花费一定的工期. 为此,除了变更对产品性能影响之外,还需要考虑变更经济成本和变更工期指标. 假设每个零件均具有固定的经济成本和时间成本,那么,一条变更传播路径的变更经济成本和工期描述为
(9)
(10)
式中: 节点vi表示当前正在发生变更的节点; costi,timei分别表示节点vi的变更经济成本和工期.
2.4 问题约束
在产品设计过程中,受各种因素的限制,一个可行的变更传播路径必须满足诸多的实际约束. 为了符合日益增多的实际需求,与已有约束多目标优化模型不同,本节全面地考虑如下5个实际约束:
约束1 节点vi不能改变,即当前变更节点cpi ≠ vi . 例如,由于技术封锁导致供应链中断或其他不可抗力,受影响的零件无法找到合适的替换零件.
约束2 节点vi必须改变,即当前变更节点cpi ≡ vi . 例如,现在使用的一个零件无法获得而重新设计的成本又超出预期.
约束3 当一个节点vi改变时,其下游节点vj必须改变,即如果cpi = vi ,且vj ∈ dsi,则cpj ≡ vj . 例如,一个节点与其下游节点密切相关,其下游节点是其重要的辅助节点.
约束4 若一个节点vi保持不变,则其下游节点vj 不能改变,即如果cpi ≠ vi ,且vj ∈ dsi,则cpj ≠vj . 例如,下游节点vj是节点vi的必不可少的辅助节点,其变化主要由节点vi决定.
约束5 当节点vi的设计变更影响ci <∆ci时,可以忽略其变更影响,变更设计结束.
2.5 优化问题描述
本文假设如下: 首先,将初始变更节点均视为单一节点,不考虑多个节点同时发生变更的情况; 其次,在设计变更过程中,不考虑中途追加变更需求的情况. 这些假设能够有效减少问题的复杂度,使本文研究更专注于问题求解. 同时考虑最小化CPI、变更经济成本、变更工期等3个目标,可将产品变更传播路径优化问题建模为如下多目标优化模型:
(11)
式中: vi ,vj ∈ CP,CPI(·),Cost(·),Time(·)分别由式(8)–(9)和(10)构成.
3 双深度Q–网络引导的多目标差分进化算法
为了克服现有DE算法搜索机制单一且不能适应问题变化的不足,Tan等尝试将DQN [29] 和DE算法相结合,提出了基于DQN的DE算法DEDQN [20],但是它依然存在如下缺点: 1)该算法使用DQN选择DE的进化策略,会使智能体陷入过度估计的困境,导致其选择的动作不一定是最优动作; 2)该算法将奖励函数设置为种群进化效率. 在处理多目标优化问题时,由于未考虑种群进化的多样性和收敛性,导致其很难获得分布均匀以及收敛的Pareto最优解集.
鉴于此,本节利用DDQN帮助进化算法自主切换不同进化策略,定义一种基于超体积测度的奖励函数,研究一种RL引导的DE算法. 此外,基于产品设计变更路径优化问题的特点,本文采用整数编码策略.
3.1 双深度Q–网络
在RL中,智能体在执行动作at后会获得一个即时奖励值rt . 为了累积奖励的最大化,需要估计动作对于未来的影响,基于此,文献 [21] 使用动作价值函数选择动作at . 动作价值函数Q(st,at)由即时奖励rt和下一时刻的状态st+1的最大动作价值构成,表达为
(12)
式中γ为折扣因子,用于平衡当前收益和未来收益.
DQN会使智能体陷入过度估计的困境. 鉴于此,学者们提出了DDQN,其神经网络由目标Q–网络和主Q–网络两个神经网络组成,但主要任务不同,主Q–网络负责选择下一个状态下最优的动作,目标Q–网络负责计算动作的价值. 这种设计有利于克服DQN中Q 值函数的过度估计问题,进一步提高模型的稳定性和学习效率 [21] . 在训练过程中,通过时间差分法不断更新Q(st,at; θt),即
(13)
(14)
式中: 是DDQN的目标函数; α是学习率,表示新信息覆盖旧信息的比率; θt和 分别是目标Q–网络和主Q–网络在当前时刻的参数. DDQN在初始训练时,随机设置主Q–网络参数θt . 在训练过程中,通过损失函数Lθ不断更新参数θt ,即
(15)
式中E(·)是平均期望.
3.2 DDQN引导的进化策略(动作)选择机制
本节使用DDQN来帮助DE提升性能. 在进化过程中,DDQN与当前种群不断进行交互,根据种群当前的状态选择合适的DE策略,并获取奖励值. 通过实时选择适合当前种群的进化策略,能够充分发挥DE在不同阶段的搜索特性.
1)状态特征.
状态特征的表示在一定程度上会影响智能体和环境的交互效果. 以最小化问题为例,当第i个个体的某一个目标函数值变小时,该个体的目标函数值之和也具有减小的趋势,因此,使用个体的目标之和来刻画种群状态的好坏. 本文将种群的状态特征st定义为
(16)
式中: ,NP是种群的大小, M是目标函数个数, 是第i个个体的第j个目标函数值. 然而,实际设计工作中,不同的目标具有不同的单位和取值范围. 为了解决上述问题,利用最小–最大规范化方法处理这些指标.
2)动作空间.
DE算法的性能主要由DE策略决定,因此选择合适的DE化策略尤其重要. 为充分发挥不同DE策略的性能,在不同阶段采取不同的进化策略. 本文使用如下3种不同的DE策略,包括DE/rand/1,DE/current to rand/1以及进化策略 DE/best/2. 由此,DDQN 的动作空间A可以表示为
(17)
在传统DE算法中,个体执行DE策略后,会出现非整数和缺失的元素,无法直接应用于产品设计变更传播路径问题中. 因此,本节通过定义算术运算符,提出了一种基于整数编码且的DE策略. 以DE/rand/1为例,具体定义如下:
(18)
式中: Hi,G表示在G次迭代时,生成的第i个新个体; Xr1,G,Xr2,G,Xr3,G表示在G次迭代时,从种群中随机选择的3个个体. ⊖的执行规则为: 首先,创建差异信息存储列表lis; 接着,获取主导个体,即个体Xr2,G,Xr3,G 中的非支配解作为主导个体,另一个则作为辅助个体,如果个体之间相互支配则从个体 Xr2,G,Xr3,G中随机选择主导个体; 最后,将主导个体和辅助个体进行比较,找出两者的差异分量,将分量存储到 lis中,并记录每个分量在主导个体中的位置. ⊕和⊗ 的执行规则为: 首先,根据中的元素个数生成相应数量的随机数; 接着,将依次生成的rand与缩放因子F进行比较,如果 rand>F 时,将lis中的分量替换掉个体 Xr1,G中相应位置的分量,从而生成新个体Hi,G.
3)奖励函数定义.
在RL中,奖励函数主要用于评价采取动作的好坏. 超体积测度(hyper-volume,HV)[30]是多目标优化算法中常用的一种两元性能评价指标. 在无需问题真实 Pareto最优解集的情况下,HV可以同时评价一个非支配解集的收敛性和多样性. 鉴于此,本文使用HV改进率作为种群进化能力的度量指标,并由此计算DDQN-DE的奖励函数值. 具体地,奖励函数rt设置如下:
(19)
(20)
式中: HVt是t 时刻种群的HV 值; δ表示Lebesgue测度,用来测量体积; |S|表示非支配解集的数目; hvi表示参照点与当前种群中第i个个体构成的超体积.
4)动作选择.
DDQN根据状态st来选择动作at ,同时获取相应的奖励值rt . 如果rt >0,那么当DDQN遇见相似种群状态时,应该选择相同的动作at . 但是,由于动作at可能仅偏向于提高种群的多样性或收敛性,DDQN连续使用该动作会使算法收敛速度过慢或陷入局部最优. 因此,一般采用ε-greedy策略进行动作的选择,以较小概率ε随机选择其他动作. ε-greedy策略的实现公式 [20] 为
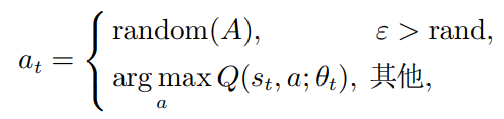
(21)
式中: rand ∈(0,1)是随机生成的数; random(A)表示从动作空间A中随机选择DE策略.
4 实验分析
4.1 测试问题与实验环境
以某型号创维电视的设计变更问题为例,验证文中所提算法的有效性. 首先,根据产品设计变更数据库获得了产品的变更传播概率矩阵,如图1所示. 接着,通过企业设计工程师的评估信息构建创维电视网络模型如图2所示. 进一步,根据企业历史变更信息,选取5个易变更的零件作为初始变更节点进行实验,如表2所示. 为了保证实验的公平性和合理性,所有算法均在Python 3.6,AMD Ryzen 55600H CPU,16.00 GB RAM环境中重复运行20次. 所提算法种群大小设置为 200,迭代次数设置为 100,根据文献 [31-32] 的建议,将交叉概率设置为0.1,缩放因子设置为0.7; 根据参考文献 [33-35] 并结合本文的研究问题,将DDQN网络的参数设置如下: α = 0.01, γ = 0.9,f = 5,更新阈值 Thresh = 10. 初始设计变更影响均设置为0.4.

图1创维电视变更传播概率矩阵
Fig.1Skyworth TV change propagation probability matrix
4.2 所提算法有效性分析
本节将所提算法DDQN-DE与5种典型的求解产品变更传播路径的算法进行比较,验证所提算法在解决多目标问题和求解方案方面的有效性和优越性. 其中,NSGA-II,基于分解的多目标进化算法(multi objective evolutionary algorithm based on decomposition,MOEA/D)和DEDQN是典型的多目标进化优化算法. Improved ACO以及最小风险路径方法(least risky change propagation path algorithm,LRCPP)均是求解产品设计变更路径时比较具有代表性的算法. Improved ACO算法是比较经典的进化优化算法,如文献 [7]、文献 [9] 均使用上述算法求解路径问题; LRCPP是传统算法中比较经典的解决算法,如文献 [36] 使用其作为对比算法. 上述5种对比算法及其关键参数设置,如下:
1)非支配排序遗传算法-II(NSGA-II)[37] . 设置种群大小为200,迭代次数为100,交叉概率为0.8,变异概率为0.1.
2)基于分解的多目标进化算法(MOEA/D)[38] . 设置种群大小为200,迭代次数为100,交叉概率为0.8,变异概率为0.1,聚合方法使用切比雪夫距离.
3)基于深度强化学习和混合变异的差分进化算法(DEDQN)[20] . 设置种群大小为 200,迭代次数为 100,初始交叉概率以及缩放因子均设置为0.5,训练回合数为100,α = 0.01,γ = 0.9,f = 5.
4)改进蚁群算法(improved ACO)[7] . 设置种群大小为200,迭代次数为100,信息素重要程度因子为0.5,启发函数重要程度因子为1,挥发速度为0.1.
5)渐进式变化传播的最小风险路径方法(LRCPP)[39] .

图2创维电视网络模型
Fig.2Skyworth TV network model
表2初始变更节点
Table2Initial change nodes

本节将DDQN-DE算法分别与3种多目标进化算法NSGA-II,MOEA/D以及DEDQN进行对比. 为了验证多目标优化算法的有效性,采用HV指标来评估算法的分布性和收敛性. 为了将NSGA-II和MOEA/D 应用到产品设计变更路径求解问题中,采用文献 [11] 提出的交叉和变异策略作为算法的更新策略.
实验结果如表3所示,“+”和“*”分别表示DDQNDE所取得的实验结果显著优于和近似于对比算法,可以看出: 1)对于表2中所有的初始变更节点,算法DDQN-DE所获得的平均 HV值均优于NSGA-II,MOEA/ DD以及DEDQN; 2)由T检验结果可知,DDQN-DE算法所得的HV值明显优于NSGA-II,MOEA/D以及DEDQN; 3)由标准差分析可知,对于节点1,DDQN-DE 算法的标准差略高于算法DEDQN; 对于节点36以及 85,DDQN-DE算法的标准差略高于算法NSGA-II. 然而,对于其余变更节点,DDQN-DE算法的标准差均优于所有对比算法,算法稳定性更好.
表3DDQN-DE算法和多目标优化算法的HV值(平均值/标准差)
Table3HV values obtained by the DDQN-DE algorithm and multi-objective optimization algorithm (mean/std)

进一步,本节将DDQN-DE算法分别与ImprovedACO算法和LRCPP算法进行对比,验证算法在求解变更方案方面的优越性. 在实验中,选择零件1(电子线)作为初始变更节点; 将3个优化目标值归一化,作为对比算法的优化目标值. 图3和图4中的红色节点分别是通过Improved ACO和LRCPP算法获得的最优变更传播路径. 图5展示了通过DDQN-DE算法获得的Pareto 最优解集.

图3Improved ACO算法的最优变更路径
Fig.3The optimal change path of Improved ACO algorithm

图4LRCPP算法的最优变更路径
Fig.4The optimal change path of LRCPP algorithm
具体路径信息如表4所示,其中P1-P3是从图5的Pareto最优解集中选取的3个变更方案; P4和P5分别是通过Improved ACO和LRCPP算法获得的变更方案. 从实验结果可以看出: 1)相比于Improved ACO和LRCPP算法,DDQN-DE算法能够同时获得多个非劣解.2)DDQN-DE算法获得的方案P1-P3各有优缺点,如方案P1的CPI值比P2,P3的CPI值小,即变更对产品综合性能影响更小; 方案P2的变更经济成本优于P1和P3; 方案P3的变更工期优于P1,P2.3)在DDQN-DE算法所得非劣解中,皆存在一个解支配ImprovedACO和LRCPP算法得到的最优变更传播路径. 例如,DDQNDE算法所得解P1支配Improved ACO的解P4,DDQNDE算法所得解 P2支配LRCPP的解P5. 综上,DDQNDE算法在求解变更方案方面优于Improved ACO和 LRCPP算法,它可以提供多个优秀的变更方案供设计者进行选择.

图5DDQN-DE算法的Pareto最优解集
Fig.5Pareto optimal solution set for DDQN-DE algorithm
表4设计变更方案
Table4Design change programs

5 结论
针对产品设计变更传播路径求解问题,本文提出了一种RL引导的产品变更路径多目标DE算法,即DDQN-DE算法. 本文给出了复杂产品网络模型,引入了变更传播模型,建立了设计变更传播路径问题的约束多目标优化模型,并且提出了DDQN引导的DE算法. 为了评估DDQN-DE算法的有效性,在某型号创维电视的设计变更问题上进行了实验,实验结果表明,所提算法的综合性能优于多目标进化算法 NSGAII,MOEA/D,DEDQN,相比于Improved ACO和LRCPP算法,所提算法可以提供多个优秀的变更方案供设计者进行选择.
尽管该研究取得了较好的结果,但它仍有一些局限性. 所提算法主要面向单变更源的产品设计问题. 在实际工程中多个零件同时发生变更的现象普遍存在,因此,多源变更设计是未来需要解决的关键问题之一.