摘要
本文主要研究不含中间缓冲区的柔性装配系统(FAS)的优化调度问题, 其中当工件竞争使用有限的生产资源时, 不合理的资源分配会导致系统死锁 (deadlock). 针对易死锁 (deadlock-prone)FAS的优化调度问题, 本文采用 Petri网建模, 提出了一种混合离散蛙跳算法(HDSFLA)以最小化最大完工时间(makespan). 首先, 提出了一种新的编码解码方法, 其中一个个体编码为一个包含全部工件加工信息的变迁序列, 可解码为一个工件–工序序列; 其次, 为了保证种群中个体的可行性, 提出了一个个体修正算法和基于最早引发时间的改进个体修正算法, 从而将不可行个体修复为可行个体; 然后, 结合编码特征设计了用于生成新个体的交叉操作; 最后, 为了平衡算法的全局搜索和局部开发能力, 设计了一个基于交换和插入算子的局部搜索策略. 通过不同规模算例上的仿真实验和算法对比分析, 验证了HDSFLA的有效性.
Abstract
This paper addresses the scheduling problem in flexible assembly systems (FAS) without intermediate buffers. In such systems, deadlock may occur when multiple jobs compete for limited shared resources under inappropriate allocation. To solve the scheduling problem of deadlock-prone FAS, Petri nets are used to model it, and a hybrid discrete shuffled frog leaping algorithm (HDSFLA) is proposed to minimize the maximum completion time, i.e., makespan. Firstly, a novel encoding and decoding method is proposed, in which an individual is encoded as a complete transition sequence and can be decoded into a sequence of jobs and operations. Then, in order to guarantee the feasibility of each individual, an individual modification method and an improved individual modification method based on the-earliest-firing-time are developed, through which an unfeasible solution can be repaired into a feasible one. Furthermore, based on the characteristics of the encoding method, a crossover operation is designed to generate new individuals for the next generation. In addition, to balance the global exploration and local exploitation capabilities of the proposed algorithm, a local search method based on swap and insert operators is developed and imbedded into the algorithm. Experimental tests on different instances and comparisons with other algorithms are conducted to demonstrate the effectiveness of HDSFLA.
1 引言
生产调度对于提升制造企业的运行效率起着至关重要的作用. 装配制造系统的调度问题,也称装配调度问题(assembly scheduling problem,ASP),由于其在实际生产中的广泛应用成为近年来的研究热点 [1-3] . 不同类型的ASP,如装配流水车间调度问题(assembly flowshop scheduling problem,AFSP)[4-6]、分布式装配流水车间调度问题(distributed AFSP,DAFSP)[7-10]、装配作业车间调度问题(assembly jobshop scheduling problem,AJSP)[11-12]、柔性装配作业车间调度问题(flexible AJSP,FAJSP)[13-15] 等,吸引了研究者们的广泛关注和研究. 相较于一般的车间调度问题,ASP不仅要考虑子组件或半成品的加工,还要考虑产品的组装,其求解更为复杂.
现有关于ASP的研究通常假设两个相邻的加工机器之间存在着容量无限大的中间缓冲区,且研究成果主要集中于AFSP [4-6] 和DAFSP [7-10],关于AJSP [11-12] 和FAJSP [13-15] 的研究还较少. Shi等 [11] 提出了一种混合遗传算法来解决以最小化makespan为目标的AJSP. Cheng等 [12] 针对一个考虑了材料完整性和装配顺序约束的AJSP,建立了一种增强模拟退火算法(enhanced simulated annealing,ESA),以最小化总完工时间和总库存时间. Zhang和Wang [13] 针对具有序列相关准备时间、工件共享和动态事件的FAJSP,提出了分别基于最早完工时间、工件最多剩余加工时间和最小工作量机器的调度规则,以解决调度和重调度问题来最小化makespan. Wu等 [14] 研究了一个以总提前/延迟时间和总花费为优化目标的分布式FAJSP,提出了一种改进差分进化模拟退火算法(improved differential evolution simulated annealing algorithm,IDESAA),其中设计了交叉、变异和选择算子用于种群更新,并设计了一种模拟退火算法用于搜索最佳Pareto解. Zhang 等 [15] 研究了一个多目标FAJSP,其中考虑了序列相关准备时间和工件在不同机器之间的传输时间,提出了一种多目标分布式蚁群方法(distributed ant colony system,DACS)来优化总工作量、总延迟和makespan. Xu 和Nagi [16] 研究了具有树结构和并行机的AJSP,并开发了一种拉格朗日松弛(lagrangian relaxation,LR)方法以最小化makespan.
上述文献虽然考虑了多种生产约束,但都没有考虑阻塞约束,即所研究的AJSP和FAJSP均假设相邻的两个加工机器之间存在着容量无限大的中间缓冲区. 而在许多实际生产系统中,如电子制造车间、自动化生产单元、钢铁工业、化工和制药厂等,由于生产环境的空间约束或产品生产技术要求,中间缓冲区是容量有限的或者不存在的,因此含有阻塞约束(零中间缓冲区)的制造调度问题近年来也吸引了越来越多研究者的关注 [7-9,17-22] .
阻塞装配作业车间调度问题(blocking AJSP,BAJSP)可以在实际工业生产中找到许多原型,如电子制造工厂、汽车制造厂等,然而,目前围绕BAJSP的研究成果是极少的 [17] . 这是因为在BAJSP中,由于生产资源(如加工机器、运输设备等)是有限的,如果资源得不到合理分配,则可能出现死锁现象,即系统是易死锁的(deadlock-prone),死锁将会导致整个或部分系统处于无限期的阻塞,无法完成加工任务 [23-24] . 死锁通常会导致系统长时间停工、一些关键或昂贵资源的低使用率以及生产效率低等结果,使得系统的关键性能指标受到严重影响. 在求解易死锁BAJSP时,需要同时考虑死锁避免和调度目标的优化,这使得调度算法的设计变得更加复杂. 现阶段只有文献 [17] 研究了一类BAJSP的变体,提出了一种混合粒子群优化算法(hybrid particle swarm opitimization,HPSO),以最小化makespan.
文献 [17] 虽然针对一类易死锁BAJSP进行了研究,但是并没有考虑工件具备柔性加工路径的情况. 因此,为此类问题设计可行且高效的调度算法仍有待研究. 本文针对一个FAJSP的变体,即一类含有并行机和批量工件、不含中间缓冲区、工件具备柔性加工路径的易死锁制造装配系统,简称易死锁柔性装配系统(flexible assembly systems,FAS),进行建模和调度问题求解的研究. 在建模方面,考虑到通过数学公式很难描述死锁且建立不等式约束来避免死锁是很困难的,以及Petri网在为制造系统建模、表征死锁、分析系统运行行为等方面表现出的优异性能 [23-24],本文采用Petri网对FAS建模; 在问题求解方面,考虑到蛙跳算法(shuffled frog leaping algorithm,SFLA)具有参数少、结构简单、易实现等特点,同时具备局部搜索和全局信息交换等特点 [25],本文采用了SFLA并结合问题特征设计了混合离散蛙跳算法(hybrid discrete SFLA,HDSFLA)来使其能够有效地求解易死锁柔性装配系统的调度问题. 仿真实验和算法比较验证了HDSFLA的有效性.
2 问题描述
2.1 柔性装配系统
本文研究的FAS可描述为: FAS包含类机器,记作能够完成类工件的加工,记作其中为方便起见,分别代表和下同. 令C(rm)表示rm的容量,即具有相同加工能力的机器rm的个数. 令φn表示待加工的Jn类工件的个数,系统中待加工工件的总数为此外,J1 类工件的工件序号表示为1,2,· · ·,φ1; J2 类工件表示为φ1+ 1,φ1+2,· · ·,φ1+φ2; J3类工件表示为φ1+φ2 + 1,φ1 + φ2 + 2,· · ·,φ1 + φ2 + φ3; 等.
在FAS中,一个产品是由多个工件经过一系列的加工和组装操作之后完成生产的. 在一个加工操作中,工件只是利用机器进行加工; 而在组装操作中,两个或多个工件组装成一个新的半成品或最终产品. Jn 类工件的一条加工路径可以表示为一个操作序列,工件可能有多条加工路径,即加工路径具有柔性. 令Ωn 表示 Jn类工件的加工路径集合,其中: ωi = oi,1oi,2 · · · oi,l · · · (ωi ∈ Ωn)为Jn类工件的一条加工路径,oi,l为ωi上的第l个操作,Li为ωi的长度. 本文中只考虑了同类工件加工路径长度相同的情况. 令R(oi,l)表示完成操作oi,l所需要的资源,于是一条加工路径与一个资源序列对应,ωi可以由资源序列R(oi,1)R(oi,2)· · · R()决定. 对于同类工件不同加工路径上的两个操作,例如,oi,l和oi′,l,如果R(oi,l)=R(oi′,l),那么 oi,l和oi′,l表示同样的操作,即ωi和ωi′上的第l个操作是相同的. 在本文中,假设FAS中所有操作所需的加工时间是预先确定且已知的,令di,l表示完成oi,l所需的加工时间.
FAS中其他约束条件为: 1)不存在中间缓冲区; 2)所有机器在0时刻可用,所有工件在0时刻可开始加工; 3)每个机器同一时刻至多只能加工1个工件; 4)每个工件任一时间最多只能在1个机器上加工; 5)任一操作一旦开始不允许中断; 6)机器的准备时间忽略不计(或包含在加工时间内).
2.2 FAS的Petri网调度模型
2.2.1 Petri网基本定义
Petri网是一个三元组N =(P,T,F),其中: P是库所集合,T是变迁集合,F ⊆(P × T)∪(T × P)为有向弧集,分别由圆圈、方框和带箭头的连接线表示; 且有对于x∈P ∪ T,•x = {y ∈ P ∪ T|(y,x)∈ F}表示x所有输入元素的集合,x• = {y ∈ P ∪T|(x,y)∈ F}表示x所有输出元素的集合.
N的状态是一个映射M : P → Z = {0,1,2,3,· · · }. 给定库所p ∈ P和状态M,M(p)表示在M下p 中托肯(token)的个数. N的任意一个状态M可以表示为一个具有初始状态M0的Petri 网称为标记Petri网,记作(N,M0).
变迁t在状态M下是使能的(enabled),当且仅当∀p ∈ •t,M(p)>0,记作M[t >. 在状态M下的使能变迁t可以引发,使得系统到达新状态M′,记作M[t >M′,其中 M′(p)= M(p)− 1,∀p ∈ •t\t•; M′(p)= M(p)+ 1,∀p ∈ t• \ •t; 否则M′(p)= M(p). 一个变迁序列β =t1t2 ∑tK如果满足Mk[tk >Mk+1,k∈ZK,且M1 = M,则称其在M下是可行(feasible)的.
2.2.2 FAS的Petri网模型
为了建立FAS的Petri网模型,需要先后为FAS中的加工路径、资源的请求和释放建模. 读者可参考文献 [26] 来更好的了解Petri网建模.
首先,Jn类工件的一条加工路径ωi = oi,1oi,2 · · · oi,l · · · 可以建模为Petri网中的一条库所变迁路径(place transition path,PT–路径),记作PTi = ,其中pi,l(l ∈ ZLi)是一个操作库所,oi,l的加工在pi,l上进行,且pi,l中托肯的个数表示正在加工的工件个数,变迁 ti,l的引发表示pi,l−1中操作的结束和pi,l中操作的开始. 方便起见,对每类工件Jn引入两个虚拟的操作库所,分别用于存储等待加工的工件和已完成加工的工件,记作pn,0和,称为开始库所和结束库所. 工件在存储位置、加工位置之间的移动用库所到变迁以及变迁到库所的有向弧表示. 对于一个操作库所pi,l,如果即pi,l有两个及以上的输出元素,则称 pi,l为分支库所,其中表示中元素的个数. 给定一个变迁ti,l,令(p)ti,l表示中的操作库所构成的集合. 如果即中包含的元素个数大于 1,则称ti,l为组装变迁. 一个组装变迁的引发表示系统中相应组装操作的开始. 由于FAS中不同的加工路径可能共享一些相同的操作,相应的,其对应的PT–路径会共享对应的库所、变迁和有向弧.
在FAS的Petri网模型中, rm类机器用一个资源库所rm表示. 资源库所rm中托肯的个数表示可用机器的数量,在系统的初始状态M0下,rm中托肯的个数 M0(rm)即为系统中rm类机器的总个数. 当操作库所 pi,l上的加工需要使用资源rm,则添加从rm到ti,l =和从到rm的有向弧表示资源的需求和释放.
整个 FAS 的Petri网模型为(N,M0)=(P,T,F,M0)=(PO ∪PS∪PE ∪ PR,T,F,M0),其中 PO,PS,PE和PR表示操作库所、开始库所、结束库所和资源库所的集合. 初始状态 M0 定义为 M0(pn,0)= φn,∀pn,0 ∈ PS; M0(p)= 0,∀p ∈ PO ∪ PE; M0(rm)= C(rm),∀rm ∈ PR.
对于操作库所pi,l中的任意一个托肯,其在pi,l中的停留时间至少为di,l,即完成oi,l所必需的加工时间. 当FAS完成加工后,其Petri 网模型对应地到达终止状态,记作 Mf,且有Mf(p)= 0,∀p ∈ PO ∪ PS; Mf()= M0(pn,0),∀ ∈ PE; Mf(rm)= C(rm),∀rm ∈ PR.
给定一个FAS及其Petri网模型,一个满足M0[α >Mf的变迁序列α称为该FAS的一个调度序列. 本文所研究的FAS调度问题为寻找一个调度序列并使得其对应的完工时间尽可能地小.
2.2.3 基于Petri网模型计算完工时间
给定一个FAS及其Petri网模型(N,M0),令π=π1,π2,· · ·,πH−1,πH表示一个满足M0[π >Mf的变迁序列,其中H为π中变迁的个数. 对于该调度序列中任意一个变迁πh(h ∈ ZH),假设πh = ti,l且其为π中第 a个ti,l,为表示更清楚,πh也可记为的最早引发时间记作根据π中变迁的顺序,πh 的引发时间不能早于πh−1的引发时间,因此有假设πh−1对应于π中的第a′个那么可进一步表示为
此外,鉴于ti,l的引发对应于操作oi,l的开始,当ti,l不是组装变迁时,即还必须在oi,l的前一个操作oi,l−1完成之后才能引发,即πh的引发时间还需满足因此对于一个非组装变迁,其中由于 ti,0 和 oi,0在FAS的Petri网调度模型中不存在,故有
当πh =ti,l为组装变迁时,即它只有在(p)ti,l中所有操作库所中的工件准备好组装时才能引发,即πh的引发时间需满足
其中为π中满足的第a个同时,πh的引发时间不能早于πh−1的引发时间,故有同时,πh的引发时间不能早于πh−1的引发时间,故有
综上,πh最早引发时间的计算公式为
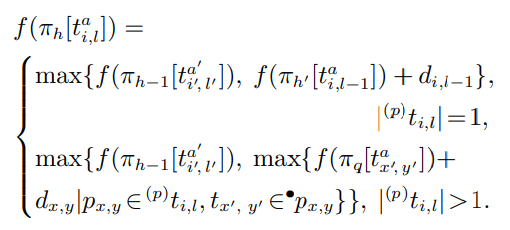
(1)
π中最后一个变迁πH的引发时间即为该调度序列对应的完工时间,记为Cmax(π)= f(πH).
例 1 考虑一个机器集为R = {rm|m ∈ Z5},工件集为J = {J1,J2}的FAS,其简单示意图见图1,其中每类资源的容量为C(rm)= 1, m ∈ Z5,待加工的工件数量为φ1 = φ2 = 5.
在该FAS中,J1类工件有一条加工路径,ω1 = o1,1 o1,2o1,3,各操作使用的机器分别为r1,r2和r5; J2类工件有两条加工路径,ω2 = o2,1o2,2o2,3和ω3 = o3,1o3,2 o3,3,ω2(ω3)上各操作使用的机器分别为 r1,r4 和r5(r3,r4和r5). 由于o2,2和o3,2使用的机器满足R(o2,2)= R(o3,2)= r4,因此o2,2 = o3,2,在Petri网模型中用同一个操作库所p2,2表示. 另外,由于系统中存在将J1类工件和J2类工件组装成最终产品的组装操作,因此,o1,3,o2,3和o3,3表示同一个操作,在Petri网模型中用 p1,3表示. 系统的Petri网模型如图1所示.

图1FAS示意图及其Petri网模型
Fig.1Example of an FAS and its Petri net model
3 混合离散蛙跳算法
为了解决FAS的调度问题,本文提出了HDSFLA 以最小化完工时间,主要包含5个模块: 个体生成与修正、个体解码、模因组划分、模因组内搜索和局部搜索.
3.1 个体生成与修正
3.1.1 编码
给定一个FAS及其Petri网模型,算法中的一个个体S编码为一个具有重复变迁的完整变迁序列S =s1,s2,· · ·,sH,即S包含从M0到达Mf所需的变迁. H的值取决于系统中待加工的每类工件的个数以及其加工路径(PT–路径)的长度.
由于系统中存在组装操作,不同类型工件的PT–路径可能拥有相同的子PT–路径,为了避免该子PT–路径上的变迁出现的次数多于一个可行S所需要的次数,为PTi定义了一个用于编码的有效(valid)PT–路径(VPT–路径),记为VPTi . 即,通过删减一些PT–路径上的相同子PT–路径以保证Petri网模型中的变迁在V– PTi中都只出现一次. 令Ti表示一个集合,由VPTi上的变迁构成. 令Θn表示由Jn类工件的VPT–路径上的变迁构成的集合,
给定一个含有类工件的FAS及其Petri网模型,Jn类工件的VPT–路径的长度记为λn,那么一个调度序列的长度为令算法种群的大小为 POP,本文采用随机方式生成初始种群中的个体,记作算法1,详细步骤如下:
步骤 1 令对于Jn类工件,如果该类工件只有一条VPT–路径,设为VPTi,则令Λn = Λn ∪ Ti; 否则,在该类工件的VPT–路径中任意选择一条,设为VPTi′,并令Λn = Λn ∪ Ti′; 重复以上操作φn次. 令
步骤 2 令h = 1,S = s1,s2,· · ·,sH.
步骤 3 随机选择Λ中的一个元素,如ti,l,令 sh =ti,l,Λ = Λ\{ti,l},h = h + 1.
步骤 4 若Λ = ∅,则输出S; 否则返回步骤3.
为方便读者理解,提供一个编码示例见附录.
3.1.2 个体修正
由于算法1得到的S是随机生成的,没有考虑系统中的各种生产约束,如工序的先后顺序和资源容量约束,以及死锁状态,因此S 可能是不可行的. 为了得到一个可行的调度序列,需对 S 进行修正使得S满足 M0[S >Mf,为此,本文提出一种个体修正(individual modification,IM)方法,记作算法2(见表1).
给定一个个体S,修正开始于初始标识M1 = M0 和S中的第1个变迁. 在算法2的第h个修正步骤中,首先检测sh是否可行(sh称为Mh下的可行变迁,当且仅当sh在Mh下使能且sh是安全变迁; sh引发后得到的新标识Mh+1是安全的,则称sh为安全变迁),如果可行则直接引发,更新标识,并开始下一步修正; 否则将 sh+1,sh+2,· · ·,sH中的第1个可行变迁sh+d(d>0)移到sh之前,在Mh下引发sh+d并开始下一步修正. 由于本文考虑的FAS中存在路径柔性,因此可能出现这样一种情况: 待检测的变迁sh+d是不可行的(即sh+d 不使能或者sh+d不安全),但是且存在是可行的,则称以上这种现象为路径冲突,即对于正在加工的、具有路径柔性的工件而言,其当前选择的加工路径是不可行的,但是存在其他的可行路径,这时通过更改工件的加工路径可完成第h步的修正. 为了快速地判定一个变迁 t 在一个给定标识M 下是否安全,算法 2中采用了一种具有多项式复杂度的死锁避免策略(deadlock avoidance policy,DAP)[27] 来进行判定.
表1算法 2 IM算法
Table1Algorithm 2 IM algorithm

在IM算法的第h个修正步骤中,算法只是在sh,sh+1,sh+2,· · ·,sH中寻找第1个可行变迁sh+d,或通过改变工件的加工路径使得sh+d为可行变迁,并没有利用与变迁引发时间相关的信息,因此得到的个体性能可能不佳. 为了保证修正后得到的个体具有良好的性能,本文还提出了一种改进后的个体修正(improved IM,IIM)算法. 在IIM的第h个修正步骤中,建立了一种最早引发时间(earliest firing time,EFT)策略来选择 Mh下具有最早引发时间的可行变迁. 具体过程为: 首先,计算Mh下具有最早引发时间的变迁t(当有多个变迁时,随机选择一个); 然后,在sh,sh+1,sh+2,· · ·,sH 中寻找t,并将sy = t 移动到 sh之前. 如果 sh,sh+1,sh+2,· · ·,sH 中不存在t,即发生路径冲突,则在修改工件路径后重新执行寻找和移动操作. EFT策略的具体实现为: 通过将IM中第12和15行中的“d + 1”替换为“执行EFT策略”,即可得到IIM(EFT策略见表2).
表2EFT策略
Table2EFT strategy

3.2 解码
对于一个可行的变迁序列S,可以将其解码为一个由工件序号和工序组成的序列,记作JO(S)= jo1,jo2,· · ·,joH,其中 joh = JNh[oi,l],JNh ∈ [1,Φ] 为工件的序号,oi,l为该工件的第l个工序. 解码的详细步骤如下,记作算法3.
步骤 1 令h = 1,JO(S)= jo1,jo2 ,· · ·,joH.
步骤 2 将sh解码为相应的工件序号和工序;
步骤 2.1 如果sh ∈Θn且即sh是Jn类工件VPT–路径上的变迁,且Jn类工件只有一条VPT– 路径,若sh =ti,l是S中第y个ti,l,则否则转至步骤2.2.
步骤 2.2 如果即sh是Jn类工件VPT–路径上的变迁,且Jn类工件有多条VPT–路径;
步骤 2.2.1 若|((p)ti,l)•|>1,且•((p)ti,l)= ∅,即sh是Jn类工件分支库所的输出变迁且分支库所为一个开始库所,如果满足t∈((p)ti,l)•的变迁在s1,s2,· · ·,sh−1中出现的次数为y,则; 否则转至步骤2.2.2;
步骤 2.2.2 若|((p)ti,l)•|>1,且•((p)ti,l)≠ ∅,即sh是Jn类工件分支库所的输出变迁且分支库所不是开始库所,如果满足t∈((p)ti,l)•的变迁在s1,s2,· · ·,sh−1中出现的次数为 y,将s1,s2,· · ·,sh−1中第 y+1个满足t∈•((p)ti,l)元素的位置记为x,则JNh = JNx,joh = JNh[oi,l]; 否则转至步骤2.2.3;
步骤 2.2.3 若,|((p)ti,l)•|=1,|•((p)ti,l)|=1 且sh=ti,l是S 中第y个ti,l,将s1,s2,· · ·,sh−1中第 y个t=•((p)ti,l)的位置记为x,则JNh = JNx,joh = JNh[oi,l]; 否则转至步骤2.2.4;
步骤 2.2.4 若 |((p)ti,l)•|=1,|•((p)ti,l)|>1,且sh =ti,l是S中第y个ti,l,将s1,s2,· · ·,sh−1中第 y 个满足t∈•((p)ti,l)的变迁位置记为 x,则JNh = JNx,joh = JNh[oi,l].
步骤 3 h=h + 1,若h=H + 1,则输出JO(S); 否则返回步骤2.
例 2 考虑一个可行个体S = t1,1,t1,2,t3,1,t1,1,t3,2,t1,3,t1,4,t1,2,t2,1,t2,2,t1,3,t1,4. 根据算法3解码后得到的JO(S)如图2所示.
3.3 模因组划分
以个体的完工时间为适应度值,则可根据公式(1)计算种群中每个个体的适应度值,记作F(S),并将种群个体按适应度值大小进行升序排序. 假设HDSFLA 包含Meme个模因组,则将排在第1(Meme + 1,2Meme + 1,3Meme + 1,等)的青蛙分配到第1个模因组,排在第 2(Meme + 2,2Meme + 2,3Meme + 2,等)的青蛙分配到第2个模因组,将排在第3(Meme + 3,2Meme + 3,3Meme + 3,等)的青蛙分配到第3个模因组,以此类推,直至将所有青蛙划分完毕.

图2一个可行个体S及其解码序列JO(S)
Fig.2A feasible individual S and its JO (S)
3.4 模因组内搜索
3.4.1 新个体生成
文中将采用两点交叉(two point crossover,TPX)操作来实现新个体的生成,TPX操作示意图如图3所示,其中P1和P2为选定进行交叉的个体,Snew为新生成的个体. 根据P1 和P2中工件的路径信息要考虑两种情况,TPX具体步骤如下:
步骤 1 随机生成h1和h2,h1和h2分别为交叉操作的起点和终点并满足 h1 ∈(1,H),h2 ∈(1,H)和h2 >h1; 本文令交叉段的长度在个体长度的1/6到1/3 之间随机生成.
步骤 2 判定P1中交叉段的元素是否在P2中都有对应元素,如果是,则将P1的交叉段复制到Snew中相应位置,把P2中与交叉段相同的元素删除后,将剩余的元素按先后顺序复制到Snew的剩余位置,见图3(a); 否则,将P1交叉段中满足对应关系的元素依次复制到 Snew中相应位置,将P2中相应元素删除后,将剩余的元素按先后顺序复制到Snew的剩余位置,见图3(b).

图3交叉操作产生新个体
Fig.3New individual generated from P1 and P2
3.4.2 模因组内个体更新
对于每一个模因组,模因组内的搜索执行NM次. 在每次搜索中,首先将模因组内的最优个体(记作Pb)与最差个体(记作Pw)进行交叉,得到新个体Pn1. 然后,对Pn1 进行修正,如果修正后Pn1的适应度值优于 Pw,则Pn1替换Pw; 否则,将种群的最优个体(记作Pg)与Pw进行交叉,得到新个体Pn2. 如果修正后Pn2的适应度值优于Pw,则Pn2替换Pw; 否则,随机生成一个新个体,修正使其可行并替换Pw.
3.5 局部搜索
为了提升算法的局部搜索能力,本文中采用了基于交换和插入算子的变邻域搜索方法(variable neighborhood search,VNS)对种群中的最优个体进行改进,基于交换算子的VNS,记作S-VNS,其执行步骤如下:
步骤 1 确定初始解S及其适应度值F(S),设k = 0,重复步骤2–步骤4直到k = LS;
步骤 2 在(1,H)内生成两个不同的随机数h3和 h4,交换S中第h3个和第h4个元素,得到的新个体记作S′,k = k + 1;
步骤 3 采用IIM修正S′,计算F(S′);
步骤 4 如果F(S′)<F(S),则S := S′.
基于插入算子的VNS(记作I-VNS)的执行步骤与 S-VNS类似,唯一不同是在步骤 2中将S中第h4个元素插入到第h3个元素之前. LS为S-VNS(I-VNS)中执行交换(插入)操作的次数.
3.6 算法流程
HDSFLA流程见图4,主要由种群初始化、解码、模因组划分、模因组内搜索及局部搜索5个模块构成.
4 实验仿真与分析
为了测试HDSFLA解决FAS调度问题的性能,进行了算例测试和算法对比实验,所有的测试算法均用 Visual Studio C++ 2019编程实现,运行环境为AMD Ryzen 7 4800HS CPU处理器,主频2.9 GHz,16 GB RAM的PC.
4.1 实验算例
由于没有可供参考的基准算例,因此以文献 [17,24] 中的制造装配系统(工件不具备柔性路径)作为参考,并对其进行扩充,得到如下一个 FAS: 资源集为 R = {m1,m2,· · ·,m6}∪ {r1,r2,· · ·,r6},工件集为 J ={J1,J2,J3},其中: {m1,m2,· · ·,m6}为一组机器,负责工件的加工; {r1,r2,· · ·, r6}为一组机器人,负责工件在相邻两个机器间的传送,其对应的Petri网模型如图5所示. 分别在[5,25]和[5,10]之间随机生成机器和机器人上操作的加工时间,记录在表3中.

图4HDSFLA流程图
Fig.4Flowchart of HDSFLA

图5测试FAS的Petri网模型
Fig.5Petri net model of the test FAS
表3工件的加工时间
Table3Processing time of operations

基于该FAS生成20个具有不同工件数量和资源配置的测试算例,记作FAS01-FAS20. 根据各算例中的资源配置将FAS01-FAS20划分为4组,每组包含5个算例,5 个算例中工件的个数(φ1,φ2,φ3)分别为(20,20,20),(30,30,30),(50,50,50),(80,80,80)和(100,100,100). 每个算例中的资源数量分别为:
HDSFLA中有4个关键参数: 种群规模POP,模因组个数Meme,模因组内搜索次数NM,局部搜索中的搜索次数LS. 本文采用实验设计方法(design of experiment,DOE)来确定算法的参数设置. 首先,给每个参数设置3个水平,然后,采用正交表L9(4=)进行实验设置,并用FAS09做测试算例. 参数的水平设置如表4所示(参数组合及对应结果见附录). 算法在每种参数组合下独立运行20 次,20次运行的平均完工时间结果作为响应值(response variable,RV),基于各参数在不同水平下的平均RV,HDSFLA的参数设置为POP = 60,Meme = 4,NM= 12和LS = 0.06H.
表4算法参数水平设置
Table4Parameters and their factor levels

4.2 算法有效性验证
对于每个算例,每种算法的终止条件都设置为 TCPU =Φ×CR×0.05 s,且算法单独运行20次. 算法在 20次运行中的最好完工时间结果和平均完工时间结果分别记作BST和AVG(小数保留两位),每个算例对应的最优结果标记为粗体.
4.2.1 算法各模块有效性验证
为了验证本文中提出的编码、IIM以及局部搜索模块的有效性,本文测试了HDSFLA和其他3种DSFLA(表示为DSFLA1,DSFLA2和DSFLA3)的性能. DSFLA1是将HDSFLA中局部搜索的IIM改为IM获得的,DSFLA2是将HDSFLA中的局部搜索模块除去后获得的,DSFLA3是将DSFLA2的编码改为现有文献 [17,28] 中的基于工件序号的编码方法后获得的. 为了保证比较的公正性,不同DSFLA都采用相同的参数设置. 实验结果如表5所示.
表5HDSFLA和其他3种DSFLA的实验结果
Table5Experimental results of HDSFLA and 3 other DSFLA

从表5中可以看出,HDSFLA的表现优于其他3种 DSFLA算法,表明了HDSFLA在求解FAS调度问题时的有效性. 同时,HDSFLA 优于DSFLA1的表现验证了IIM的有效性,HDSFLA优于DSFLA2的结果验证了局部搜索模块的有效性,DSFLA2远优于DSFLA3 的结果表明了本文提出的编码方式对于提升算法求解质量有着显著的效果. 此外,算法性能还存在统计意义上的差异,也说明了HDSFLA中不同模块的有效性,实验结果和分析见附录.
4.2.2 HDSFLA与其他算法对比
由于FAS的生产特点以及死锁的存在,目前无可用的调度算法能够解决其调度问题,故选用几种尽可能相关的调度算法以及几种著名的算法作对比实验. 以HPSO [17],GA [28],GA2,灰狼算法(grey wolf optimizer,GWO)[29],基于成功历史的自适应差分进化算法(success-history based adaptive differential evolution,SHADE)[30] 和jSO [31] 为对比算法,其中HPSO是用于求解不含柔性路径FAS调度问题的算法,GA用于求解含有柔性路径、不含装配操作的柔性制造系统调度问题,GA2由GA改进得到,GWO,SHADE和jSO为近年来群智能和进化计算领域较为著名的算法. 由于这些算法无法直接用于解决FAS调度问题,故做以下调整: 同时考虑文献 [17,28] 中基于工件序号的编码方式,修改为适用于 FAS 调度问题,应用到 HPSO,GA,GWO,SHADE 和jSO中; 将文献 [28] 中的个体修复方法与文献 [27] 中的DAP结合来修正 HPSO,GA,GWO,SHADE和jSO中的不可行个体. GA2是将GA中的编码、个体修复、解码、交叉操作更换为本文提出的编码、个体修正、解码和交叉操作后得到. 比较算法的其他方面与来源参考文献保持一致. 实验结果如表6所示.
表6HDSFLA和6种比较算法的实验结果
Table6Experimental results of HDSFLA and 6 comparison algorithms

由表6可知,HDSFLA在各算例上的BST和AVG结果均优于其他比较算法,表明了HDSFLA在求解FAS 调度问题时具有优异的性能. 同时,GA2算法优于GA,不仅表明了本文所设计的编码和交叉操作也适用于设计其他算法,还表明了其有效性.
5 结论
本文研究了易死锁柔性装配系统的调度问题,以完工时间为优化目标,提出了HDSFLA. 首先,建立了系统的Petri网模型; 然后,基于Petri网模型建立了HDSFLA,包括编码方法、个体修正方法、改进的个体修正方法、解码方法、生成新个体的交叉操作和局部搜索方法; 最后,设计了对比实验验证了HDSFLA中所设计的不同模块的有效性,与其他算法的对比表明了 HDSFLA在求解易死锁柔性装配系统调度问题方面有着较强的优势.
鉴于针对柔性装配系统调度问题的研究尚处于初步阶段,在后续研究中将继续关注以下几个方面: 1)探索在优化能力和计算效率方面具有更好表现的求解算法,如研究建立具有更低复杂度的个体修正方法、基于问题特征知识的搜索策略等; 2)进一步关注具有其他生产约束的柔性装配系统,如准备时间、不确定加工时间、零等待和随机事件等; 3)考虑其他性能指标的优化,如能耗、总提前/延迟时间、总流经时间等.
附录
附件 https: //pan.baidu.com/s/1QLIUPzCM3gJhK0mY9 JhJkQ; 提取码: 0331