摘要
针对全厂过程的复杂非线性动态特征, 本文提出了一种分布式的过程监测方法. 它包括两个主要内容: 基于copula entropy Louvain(CE-Louvain)的过程分解和基于动态递归支持向量数据描述(DR-SVDD) 的故障检测. 首先, 根据机理知识将全厂过程中的变量初步映射为和过程结构相对应的无向图模型, 引入CE来描述无向图中不同节点(即过程变量)之间的权重, 并基于将CE-Louvain算法精细分解为合理的子块. 然后, 针对每个子块提出了基于 DR-SVDD的分布式故障检测方法以提高故障检测率. 最后, 利用贝叶斯融合推理方法得到全局过程监测结果. 提出的方法在Tennesse-Eastman(TE)过程中得到了验证.
关键词
Abstract
A distributed process monitoring method is proposed for the complex nonlinear dynamic characteristics of the plant-wide process. It consists of two main elements: process decomposition based on copula entropy Louvain (CELouvain) and fault detection based on dynamic recursion support vector data description (DR-SVDD). Firstly, the variables in the plant-wide process are initially mapped into an undirected graph model corresponding to the process structure based on the mechanistic knowledge, and CE is introduced to describe the weights between different nodes (i.e., process variables) in the undirected graph, and the CE-Louvain algorithm is finely decomposed into reasonable subblocks based on the CELouvain algorithm. Then, a DR-SVDD-based distributed fault detection method is proposed for each sub-block to improve the fault detection rate. Finally, the global process monitoring results are obtained by using Bayesian fusion inference method. The proposed method is validated in the Tennessee-Eastman (TE) process.
1 引言
随着现代自动化系统的广泛应用和信息技术的迅猛发展,现代过程工业日益规模化、复杂化. 全厂过程的监控在大型工业生产中引起了相当大的关注,尤其是那些使用工业信息物理系统的大规模工业过程 [1-2] . 全厂过程通常由位于不同区域的不同车间、作业部门、部门,甚至几个工厂构成全厂流程 [3] . 与小型工业过程不同,全厂过程的数据收集、管理和存储更具挑战性. 传统基于模型的监控方法难以适应于大规模、复杂工业过程. 近年来,大数据分析成为企业提供工业价值的主要动力,使工业生产更加智能化 [4-5] . 基于数据的过程监控方法变得更具可行性,可用于复杂的全厂工业过程.
与采用集中监控技术的小规模工业过程不同,全厂范围监控需采用多块策略,将过程变量划分到不同的子块中进行监控 [6] . 当发生故障时,故障可能只影响一个或几个子块,这种局部故障显然很难通过集中式的模型检测到. 目前,出现了许多分布式故障检测方法. 这些方法将过程变量划分为若干的子块,块中的过程变量通常具有更强的相关性,然后在这些划分的块中构建各自的监控模型,如主成分分析(principal component analysis,PCA). 最后,将所有模块的监控结果组合起来进行全过程监控 [7] . 过程变量的块划分在分布式过程监控中起着重要作用,它寻求将相关变量聚类到同一个块中. 然而,很难为分布式过程监控构造一个有效的过程变量划分方法.
到目前为止,过程变量划分方法主要分为两种类型: 基于机理和数据驱动. Jiang等人 [8]基于机理知识将过程变量分解为5个子块,然后构建分布式变分贝叶斯概率模型进行监控. Huang和Yan [9] 提出了基于互信息的自相关变量划分方法. Xu等人 [10] 使用最小冗余最大相关(max relevance and min redundancy,mRMR)方法进行变量分解. 该方法既减少了冗余,又保持了不同变量之间的最大相关性. Zeng等人 [11] 提出基于互信息的稀疏多块方法,生成与过程机制相关的易于解释的子块.
上述过程变量分解方法都有各自的局限性. 基于机理的方法需要详细的先验知识,分解效率缓慢. 数据驱动方法具有随机性,可能错误地使地理位置相距较远、实际相关性较小的变量划分至同一个子块,降低了监控效率和检测精度. Li等人 [12] 提出了一种基于图模型的过程变量分解方法,得到了更合理的过程变量划分结果. 图模型可以将工业过程中的机理知识和变量之间的相关性结合,得到更加合理的过程变量分解结果.
在图模型中,变量相关性的度量是一个重要问题. Ma和Sun [13] 借助copula函数提出了一种新的度量变量相关性的方法,即copula entropy(CE). CE是一种描述变量间依赖性的多元概率分布函数,提供了变量相关性的不确定或随机度量,可以度量非线性,全阶次的变量之间的相关性. Tian等人 [14] 提出了一种基于加权copula的多块主成分分析方法,证明了CE可以有效的估计变量间的相关关系. 因此,在图模型中引入CE 进行过程变量分解.
过程监控目的是将工业过程中的故障样本与正常样本分开. 流行的数据驱动监控方法分为多元统计过程监控方法(multivariate statistical process monitoringmethods,MSPMs)和机器学习方法 [15] . 其中,全厂过程多元统计过程监控方法的方法包括分布式主成分分析 [16]、分布式典型相关分析 [17]、分布式偏最小二乘法 [18] 及其扩展. MSPMs通常假设过程数据是线性的和高斯分布的,这在实际生产过程中并容易不满足. Tax和Duin [19] 将正常样本视为一类,提出构建支持向量数据描述(support vector data description,SVDD)模型来区分错误样本和正常样本. SVDD没有过程数据的高斯限制,可以扩展到非线性情况,相比其他方法,具有一定的优越性. Zhang等人 [20] 提出一种基于自适应半径的分布式间隙SVDD的全厂过程监测框架,将间隙度量和 SVDD模型相结合,用于提高检测性能. Wang等人 [21] 提出了MI-Louvain-DSVDD方法,将 SVDD模型应用于全厂的分布式过程监控,已被证明比经典方法具有更好的监测结果. 然而,在实际工业环境中,过程运行中普遍存在动态时变特征,上述监控模型不能随过程变化而更新. 为了进一步提高动态过程的监测精度,通常构建自适应动态监控模型,其中递归法是具有代表性的自适应监控策略 [22] .
针对上述分析,本文提出了一种基于CE-Louvain 分解和动态递归 SVDD(dynamic recursion SVDD,DR-SVDD)监控的分布式监控方法(copula entropy DR-SVDD,CE-DR-SVDD). 在该架构中,利用所提出的CE-Louvain算法将机理知识与数据分析相结合,实现过程变量分解. 然后,基于提出的DR-SVDD方法为每个子块构建监控模型. 最后,通过贝叶斯融合决策得到全局过程监控指标,从而进行全厂过程的全局监控. 总之,本文的贡献如下:
1)针对全厂过程监控问题,提出一种新的基于 CE-DR-SVDD的分布式监控策略,并基于贝叶斯决策获得全局监控结果;
2)提出了CE-Louvain算法用于过程变量分解,融合了机理知识和变量相关性,获得了合理的变量划分结果;
3)针对复杂非线性动态过程,提出了DR-SVDD 模型进行监控,取得了良好的结果.
2 分布式监控框架和过程变量分解
2.1 整体框架
本研究的整体框架如图1所示. 具体实施由3部分组成(从上到下):
1)基于所提出的CE-Louvain算法进行过程变量分解. 该算法基于CE和机理知识构造加权图模型,然后通过CE-Louvain算法分解为p个子块;
2)基于所提出的DR-SVDD方法,为每个子块构建局部监控模型,进行局部子块的故障检测;
3)基于贝叶斯融合推理将所有子块的故障检测结果进行概率融合,得到全局的故障检测结果,从而进行全厂过程的全局监控.

图1分布式监控框架
Fig.1Distributed monitoring framework
2.2 基础知识
1)Copula熵能够估计多变量之间的相关关系. 假设X是具有边缘分布u和copula密度c(u)的随机变量,则X的copula熵Hc(X)定义为
(1)
其中
2)无向图模型的定义如下:
(2)
其中:代表顶点集; 代表无向边,×表示笛卡尔积. 假设将一个工业过程中的4个变量映射为如图2所示的图模型.

图2无向图模型
Fig.2Undirected graph model
图2中: 顶点A, B,C,D代表4个过程变量,顶点之间的无向边代表变量之间存在物理上的关联. 若定义边权重,则可根据图模型写出权重矩阵. 图模型直观的反映出工业过程的变量之间的关联,然后根据图模型划分算法,可以将过程变量划分为合理的子块.
2.3 基于CE-Louvain的过程变量分解
针对全厂过程中采集到的高维复杂数据信息,本文对已有的Louvain算法进行了优化,提出了一种基于CE相关性的过程变量分解方法.
首先将全厂过程中的变量构造成一个加权图模型,其中图模型中节点代表全厂过程中的变量. 然后利用图模型划分子块. 基于节点之间的权重,可以将节点划分到与其相关性最大的子块. 在权重矩阵的构造中,结合了机理知识和数据,克服了纯知识和数据驱动分解方法的缺点,提高了流程分解结果的合理性.
假设数据矩阵是从全厂过程正常状态下收集的,其中: m代表变量数,k代表样本数. 引入机理知识构造图模型,若物理上第r个和第l个变量之间没有关联,则令图模型中两个顶点之间的权重zrl = 0; 若物理上第r个和第l个变量之间相关联,则令图模型中两个变量之间的权重最终,图模型中的权重矩阵Z的构造如下:
(3)
一个好的子块划分结果的表现形式是: 在子块内部的变量相关性较高,而在子块外部变量的相关性较低. 本研究采用模块度(Modularity)衡量一个子块的划分是否优良. 模块度M的定义如下:
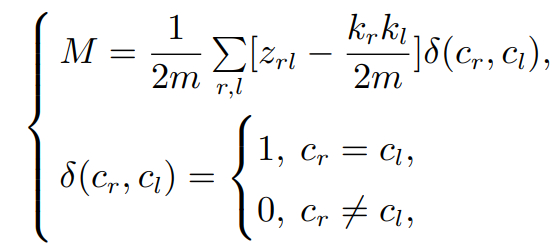
(4)
其中: zrl为连接顶点r和l的边的权重; 代表与顶点l连接的边的权重之和; 代表与顶点r连接的边的权重之和; cr代表顶点r所属的子块.代表所有边的权重之和.
步骤 1 将图模型中的每个顶点作为一个子块,子块个数与顶点个数相同.
步骤 2 依次将每个顶点与之相邻顶点合并在一起,计算它们最大的模块度增益∆M是否大于0,如果∆M >0,就将该顶点放入模块度增益最大的相邻顶点所在子块. 其中模块度增益∆M的计算方式如下所示:
(5)
步骤 3 迭代步骤2,直至算法稳定,即所有顶点所属子块不再变化.
步骤 4 将各个子块中所有的顶点压缩成为一个新顶点. 其中,子块内的权重转化为新顶点环的权重,子块间的权重转化为新顶点边的权重.
步骤 5 重复步骤1–4,直至模块度M的值不再变化.
子块划分完成后,矩阵X被划分为互不重叠的p个子块,可以表示为
(6)
3 基于CE-DR-SVDD的分布式故障检测
3.1 构造增广数据矩阵
在任意子块µ中,用Xµ表示第µ个子块中mµ个变量在k个时刻的采样数据. 当未引入时滞s时,子块µ 中的数据矩阵Xµ如下所示:
(7)
其中i = 1,2,· · ·,k. 当引入时滞s后,构建增广数据矩阵Xµ(k,s),即
(8)
其中:
值得指出的是,为处理动态特性,增广数据矩阵中引入时滞s值. 较大的时滞需要更长的历史数据来捕捉系统的动态行为,这可能增加了模型的复杂度和计算成本. 较小的时滞系数可能无法充分捕捉系统动态的延迟特性,从而导致模型对系统行为的描述不够准确和完整. 选择适当的时滞系数可以在准确性和模型复杂性之间进行权衡,合适的参数可实现检测准确性和模型复杂性的平衡,时滞系数的选择一般通过交叉验证法确定.
3.2 基于DR-SVDD的局部故障检测
在任意子块µ中,将增广数据矩阵Xµ(k,s)投影至超球体空间,找到一个具有最小体积的超球体来容纳所有训练数据Xµ(k,s). 寻找最小体积超球体的方法可以写成如下优化问题:
(9)
其中: aµ和Rµ分别是超球体的中心和半径; C是惩罚参数; ξi是松弛变量. 通过使用拉格朗日乘数法,优化问题的对偶形式可以表示为
(10)
其中: K(xi,xj )= ⟨Φ(xi),Φ(xj )⟩是描述了高维空间中的内积的核函数; αi是拉格朗日乘数; xi和xj是训练数据集Xµ(k,s)中第i个和第j个训练样本. 把拉格朗日乘数符合0 ≤ αi≤ C的样本称为支持向量. 则超球体球心aµ,k和半径Rµ,k的计算如下:
(11)
(12)
(13)
其中x0 ∈ SV .
假定新收集的实时数据为x(k + 1),当引入时滞s 后,实时测试样本数据被构造为 xk+1 = [x(k + 1)x(k)· · · x(k + 1 − s)],xk+1与超球体中心aµ,k之间的距离dµ,k+1为
(14)
如果Du,k+1 >Ru,k,则认为实时数据xk+1在超球面之外,为故障数据; 如果Dµ,k+1 <Rµ,k,则认为实时数据 x(k + 1)为正常数据,将其加入训练数据集 Xµ(k,s)并去除最旧的数据 x1. 此时,训练数据集 Xµ(k,s)被更新为Xµ(k + 1,s),同样的超球体半径被更新为Rµ,k+1.
由于考虑到了数据的动态特性,理论上动态递归支持向量数据描述模型能更好的检测出实际工业过程中存在的时序相关特性故障.
3.3 贝叶斯融合决策
基于动态递归支持向量数据描述算法,得到了各个子块的监测模型,通过贝叶斯推理对各个子块的监测统计量进行概率相加,得到贝叶斯综合统计量(Bayesian inference comprehensive,BIC),实现全局监控 [23] . 首先计算子块中的实时监测结果dµ,k+1的条件概率,转换方法如下所示:
(15)
其中:“N”为正常状态; “F”为故障状态; dµ,k+1为第µ个子块新样本x(k + 1)的统计量; Rµ,k为第µ个子块的控制限. dµ,k+1的故障概率被计算为
(16)
(17)
其中P(N)和P(F)是过程正常和异常的先验概率. 当显著性水平选择为α时,P(N)和P(F)的值可以确定为1 − α和α. 最终,BIC计算如下所示:
(18)
其中BIC的置信度阈值确定为α. 实时样本投影在BIC 的置信区间内表示整个过程正常运行,而投影到外部则表示出现了故障.
3.4 CE-DR-SVDD过程监控流程
基于CE-DR-SVDD的过程监控包括3个阶段: 离线训练、局部在线监控、全局在线监控. 在离线训练阶段,全厂过程变量被CE-Louvain算法划分为p个不同的子块. 然后基于DR-SVDD算法为每个子块训练局部故障监测模型. 局部在线监测阶段使用设计的监测模型监测各个子块的是否有故障发生. 全局在线监控基于贝叶斯融合决策得到全局的故障监测结果. 整个过程监控的流程如图3所示.

图3CE-DR-DSVDD过程监控流程图
Fig.3CE-DR-DSVDD process monitoring flow chart
4 仿真验证
4.1 TE过程介绍
TE过程由Eastman化学公司创建,目前被广泛用于验证过程监控方法 [24] . 如图4所示.
TE过程模拟了一个实际的工业化工过程,由5个典型的操作单元组成: 反应器、冷凝器、气液分离器、产品剥离塔和循环压缩机. TE过程收集了52个测量变量,其中变量1–22为过程测量,变量22–41为成分测量,变量42–52为操作测量. TE过程设置了21个不同的故障,其中故障1–7是由过程变量的阶跃变化引起的; 故障8–12是由过程变量的随机变化引起的; 故障 13是由反应动力学特性的变化引起的; 故障14–15和 21是由阀门粘连引起的; 故障16–20有未知的故障类型. 每个故障数据的前160个样本是正常的,其余161 –960个样本是引入故障后测量的.
4.2 案例分析
由于 TE过程中成分测量变量与其他变量的采样间隔不同,并且成分变量获取所需的数据需要更高的成本和复杂性. 因此,本研究从TE过程52个变量中选择了22个过程测量变量和11个控制测量变量,共33 个采样间隔均为3分钟的变量进行建模. 根据所提的过程变量分解方法,33个变量被划分为6个子块. 根据所提的过程变量分解方法,33个变量被划分为6个子块. TE过程变量划分结果如表1所示. 子块变量分解过程如图5所示.
表1TE过程变量的划分结果
Table1Results of the division of TE process variables


图4TE过程
Fig.4TE Process

图5子块划分过程
Fig.5Sub-block division process
首先基于机理知识将过程变量进行粗分解,将同一单元及与单元相邻的连接变量粗略划分在一起,共得到5个子块. 然后,基于CE-Louvain算法进行精细分解,将物理上相邻单元且相关性较强的变量划分在一起,得到 6个子块,比如子块 2中聚集了反应器(变量 7)、分离器(变量11,13)、汽提塔(变量16,18,19,50)和压缩机(变量20,46)等变量,分别属于物理上相互连接的4个单元,且相关程度大.
故障检测模型的性能通常用误报率(false alarm rate,FAR)和故障检测率(fault detection rate,FDR)来量化 [21] . FAR衡量的是故障检测的误报概率,FDR衡量的是故障检测的成功率. 这些性能指标将用于讨论所提出方法的鲁棒性和检测灵敏度,并评估所提出方法的性能. 两个指标的定义如式(19)所示.
(19)
其中: NFAR是在测试数据集中被检测为故障但实际上正常的样本数; Nn是测试数据集中正常样本的数量; NFDR是成功检测到的故障样本数; Nf是测试数据集中错误样本的数量. 因此,如果FAR接近0,FDR 接近1,则监控性能较好.
本节基于CE-SVDD,SVDD,DCCA [17],MI-Louvain-DSVDD [21],分布式CE-DR-SVDD等5种过程监控方法,对TE过程进行过程监控分析. 其中 CE-SVDD 方法为分布式CE-DR-SVDD方法的消融实验,通过将局部过程监控模块替换为原始SVDD模型,对比所提方法的有效性; SVDD方法表示传统的集中式过程监控模型; DCCA [17] 与MI-Louvain-DSVDD [21] 方法是前人所提出的分布式过程监控方法.
在离线建模阶段,采用TE过程训练数据集中正常工况下的样本数据建立过程监控模型. 其中SVDD及其相关模型中的惩罚参数C设置为0.1,松弛变量ξi设置为11,故障检测显著性水平α设置为0.05,时滞系数 s设置为2.
5 种不同方法对 TE过程21种不同故障的FAR和 FDR的检测结果如表2所示,其中,最大FDR的结果已加粗显示. 从消融实验CE-SVDD方法的仿真结果可以看出,当分布式监控框架的局部监控模块采用传统SVDD模型时,21种故障的FAR结果都为0,但是同时FDR结果低于所提方法,并且对一些故障变得更难以检出,比如故障 3,4,5,9,15,16 和19,这些故障的 FDR结果都小于0.3. 当考虑过程变量的动态特性时,将局部过程监控模型设计为DR-SVDD模型后,21种故障的FDR结果均有提高,该消融实验证明了所提方法对工业过程监控的有效性.
另外,从表2中可以直观的看出,相比其他已有方法,所提出的方法对TE过程的18个故障获得了最好的监测结果,主要原因是所提的变量分解方法和 DRSVDD算法能够很好地描述变量之间的动态特性. 故障1和2的检测结果即使不是最好的,也只是略低于最好的结果. 具体而言,对于故障1,2,4,6,7,8和14,5种方法的FDR都接近1. 当监测故障3,9,10,11,15,16,19,20,21时,所提出的方法远优于其他4种方法. 对于故障3,9和15,由于故障量级较小,大多数监测方案无法检测到它们,尽管如此,所提出的方法在一定程度上提高了检测性能. 对于故障1,6,13,18,19,所提方法在保证更高FDR的同时使FAR= 0,取得了极好的结果.
表2TE过程变量的划分结果
Table2Results of the division of TE process variables

进一步分析 SVDD、分布式 CE-DR-SVDD和MILouvain-DSVDD3种方法对故障5和故障13的检测结果,以便更好的说明所提方法的优越性.
故障5反映了冷凝器冷却水入口温度的阶跃变化. 当温度呈现阶跃变化时,会导致冷凝器冷却水流量阶跃变化. 故障发生时,冷凝器出口到汽液分离器的流速增大,导致汽液分离器温度呈上升趋势,分离器冷却水出口温度升高. 控制回路系统补偿故障状态并将分离器的温度拉回到默认温度. 图6(a)–(c)分别表示了 3种过程监控方法对故障5的监测结果. 可以看出,3种方法都检测出了系统发生的变量,但本文所提方法相比另外两种取得了更高的FDR,证明了CE-DR-SVDD模型对系统内故障的检测效果.
故障13反映了系统反应动力学特性发生变化而导致的缓慢漂移故障. 当TE工艺引入此故障时,反应器温度和压缩机进料将出现异常,化学反应可能无法按预期进行,甚至后续产品都可能受到影响. 图7(a)–(c)分别表示了3种过程监控方法对故障13的监测结果. 本文所提的CE-DR-SVDD模型相比其他方法具有更高的FDR,且对故障13中的FAR= 0,体现了该模型相比其他方法的优越性.

图6故障5过程监控结果对比
Fig.6Comparison of process monitoring results for fault 5
通过上述对比,表明了本研究所提出的过程检测方法的有效性. 因此,本研究所提出的方法有望用于监测具有分布式操作单元的全厂过程.
5 结论
本文提出了一种CE-DR-SVDD分布式过程监控方法. 所提出的CE-Louvain算法将图模型理论应用于过程分解. 该分解策略结合了机理知识和数据,克服了纯知识和数据驱动分解方法的缺点,提高了流程分解结果的合理性. 基于分布的DR-SVDD算法,在每个子块中构建故障检测模型. 最后将各子块的故障检测结果基于贝叶斯融合决策方法进行概率融合,得到全局监控结果. 所提方法在TE过程中进行了测试,监测结果验证了其有效性.
当检测到故障发生后,还需要考虑故障定位、故障分类等问题. 因此,未来的工作将集中在设计一种适合该模型的故障定位、故障分类方法以解决实际生产应用问题.

图7故障13过程监控结果对比
Fig.7Comparison of process monitoring results for fault 13