摘要
粒子滤波对非线性非高斯系统具有较好的估计性能, 但引入重采样技术后, 粒子多样性匮乏一直是影响粒子滤波估计精度的关键问题. 为此, 本文提出一种混合自适应重采样的智能粒子滤波方法, 该方法首先在混合自适应Metropolis-Hastings(M-H)重采样基础上设计了高斯变异的自适应协方差矩阵计算函数; 其次, 提出了采用“优胜劣汰”模式的接受拒绝准则函数; 最后, 对有效粒子集合进行实时更新, 改善了粒子集合的粒子质量并提高了粒子滤波的精度. 利用两个一维非线性模型和一个高维非线性模型进行仿真, 以验证本文方法的有效性. 实验结果表明, 与现有重采样方法相比, 本文方法能够有效地改善重采样后的粒子质量, 提高粒子滤波的估计精度.
Abstract
Particle filter (PF) has good estimation performance for nonlinear and non-Gaussian systems, but the lack of particle diversity has always been the vital problem affecting the estimation accuracy of PF after the introduction of resampling technology. Therefore, an intelligent PF method based on hybrid adaptive resampling is proposed. Firstly, a function of computing the covariance matrix adaptively for Gaussian variation is designed in this method on the basis of hybrid adaptive Metropolis-Hastings (M-H) resampling. Secondly, an acceptance and rejection criterion function using the mode of survival of the fittest is developed. Finally, the effective particle set is updated in real time to improve the quality of the particle set and the accuracy of the PF. Two one-dimensional nonlinear models and one high-dimensional nonlinear model are used to verify the effectiveness of the proposed method. Experimental results show that the proposed method can effectively improve the quality of the particle after resampling and improve the estimation accuracy of the PF compared with the existing resampling methods.
1 引言
由于随机噪声干扰的影响,传感器的测量值会包含误差,利用滤波技术可通过对这些带噪声的量测数据进行处理以获得系统的状态最优估计值. 线性高斯系统的最优滤波方法是卡尔曼滤波(Kalman filtering,KF),但在实际应用中几乎大部分系统都包含非线性和非高斯的因素,这些因素影响了卡尔曼滤波的估计精度 [1] . 粒子滤波(particle filter,PF)不受系统模型线性程度和噪声高斯特性的约束且易于实现,逐渐引起了国内外研究者的广泛关注 [2-4] . 粒子滤波通过随机抽取一些加权的粒子逼近后验概率分布,利用粒子的加权求和代替高维积分估计系统状态. 与卡尔曼滤波相比,粒子滤波对非高斯非线性滤波问题具有更强的解决能力,但其存在的粒子退化问题严重影响了估计精度和效率 [5-7] . 为此,Gordon等人 [8] 在1993年提出了重采样技术,通过复制高权值粒子、舍弃低权值粒子提高粒子对后验概率分布的逼近程度,进而提高粒子滤波的估计精度. 此方法确实增加了有效粒子数量,但大量复制高权值粒子、舍弃低权值粒子会促使多数粒子都聚集在同一区域,后验概率分布有大量的高概率区域未被有效覆盖,即出现了粒子多样性匮乏的问题,从而使滤波结果出现大的偏差 [9] . 因此,如何改进粒子重采样策略解决粒子多样性匮乏问题,成为提高粒子滤波估计精度的关键问题.
目前,针对粒子多样性匮乏问题,国内外学者做了大量的研究. 文献 [10] 提出了一种确定性重采样策略,避免盲目舍弃低权值粒子,从而提高了粒子多样性. 徐诚等人 [11] 提出了一种基于误差椭圆重采样的粒子滤波跟踪算法,使用不同置信概率建立误差椭圆,基于几何距离把粒子集划分为不同等级,对粒子进行分级采样,进而解决目标定位跟踪问题. 上述改进重采样方法虽然具有一定的效果,但仍然是基于传统重采样的思路,并没有从根本上解决粒子多样性匮乏的问题. 近年来,群智能优化算法的发展为提高粒子多样性提供了新的思路. 文献 [12-14] 分别将人工鱼群算法、萤火虫算法和自控蝙蝠算法引入粒子滤波的重采样中,以粒子权值为目标函数,利用群智能优化算法优化粒子权值以改善粒子分布. 这类方法从一定程度上缓解了粒子多样性匮乏的问题,但在群智能优化方法优化粒子的过程中,每一时刻都需要运行一次完整的优化方法迭代过程来寻求最优解,这使得计算复杂度大幅增加,严重影响了算法的实时性,同时大部分群智能优化方法都存在易陷入局部最优的问题,粒子滤波的估计精度会受到严重影响,所以此类方法有待于进一步改进. Yin等人 [15-16] 和吴昊等人 [17] 分别提出了遗传算法的智能粒子滤波算法,将遗传算法的交叉和变异算子融入到粒子重采样中,以驱使低权值粒子向高概率区移动,为解决粒子多样性匮乏提供了一种新思路. 基于这类方法的思路,文献 [18] 进一步提出了一种自适应遗传粒子滤波器(adaptive genetic PF,AGPF),该方法设计了自适应调整变异概率的策略,将交叉操作与自适应变异算子相结合进行重采样,然后将该方法应用到姿态估计系统.2020年,Moghaddasi [19] 进一步引入精英算子和轮盘赌选择机制对粒子交叉变异步骤进行改进,提出基于遗传算法的简化粒子滤波方法(reduced PF based upon genetic algorithm,RPFGA),提高了重采样的效率,并将其应用至实时视频目标跟踪.2021年,文献 [4] 针对粒子多样性匮乏的问题,通过选择、粗化、分类、交叉和变异5 种操作优化重采样粒子分布,将其整合至粒子滤波框架中,形成基于遗传优化重采样的粒子滤波(genetic optimization resampling based PF,GORPF). 同时文献 [20] 提出了自适应Metropolis-Hastings(M-H)重采样算法,利用M-H与交叉和高斯变异策略相结合的方法对粒子进行重采样,增加了中、高权值粒子的数量,有效抑制了粒子多样性匮乏. 上述方法通过利用遗传算法的交叉和变异策略增加粒子的多样性,对于粒子滤波重采样的发展具有重要意义. 然而,随着不断地改进,重采样策略变得越来越复杂,需设置的参数也逐渐增多,使得这些方法可实现性变差,所以此类方法也亟需进一步改进.
因此,本文提出一种混合自适应重采样的智能粒子滤波方法来提高粒子多样性. 首先,在现有M-H重采样的基础上,根据高权值粒子分布情况自适应计算高斯变异的协方差矩阵,改善重采样后高权值粒子的质量; 其次,改进新粒子接受拒绝规则,采用“优胜劣汰”模式接受高权值粒子、摒弃极低权值粒子,避免极低权值粒子被接受影响粒子滤波估计结果; 最后,改进有效粒子集合更新方式,将接受的新粒子实时地增加到高权值粒子集合中,以保证新粒子信息在下一个粒子采样时能够被利用,从而克服当高权值粒子较少时新粒子分布较集中的问题. 最终通过常用的一维模型和高维模型对该方法的有效性进行验证.
2 问题描述
假设非线性离散系统模型描述如下:
(1)
(2)
式中:和分别为k时刻的系统状态向量和观测向量,为过程噪声,为观测噪声,f(·)和h(·)分别为状态转移函数和测量函数.
设系统的状态转移概率密度为,系统状态的观测似然概率密度为,系统状态的初始先验概率密度为. 假设k时刻系统的状态序列为,系统的观测序列为 . 根据贝叶斯原理,系统状态的后验概率可以通过以下两步得到:
1)预测.
(3)
2)更新.
(4)
式中
(5)
由于后验概率分布 的解析解很难求得,所以根据大数定理和蒙特卡洛原理,从 中抽取大量样本(即粒子)来逼近 ,从而根据下式计算的估计值:
(6)
式中:为归一化后的粒子权值,N为粒子数.
然而在实际问题中,直接从中抽取粒子较为困难,所以在此引入一个较为容易采样的重要性概率密度,并确定粒子权值为
(7)
随着算法不断迭代,粒子退化问题逐渐凸显. 大部分粒子的权值变得极低,只有少数具有较高权值的粒子起到决定作用. 这导致粒子滤波大量的运算成本被浪费,估计精度大幅度降低. 为缓解粒子退化问题,Gordon等人增加了重采样技术,以等权值粒子逼近后验概率分布,然而,这种改进却带来了新的问题. 由于重采样时根据权值大小进行复制,许多高权值粒子被保留,而低权值粒子被大量舍弃,这导致具有相同权值的粒子越来越多,不同权值的粒子逐渐减少,粒子多样性出现了匮乏. 重采样后的粒子分布如图1所示,在后验概率分布中,仅仅有少数高概率区被覆盖,很多高概率区仍然没有被粒子覆盖(浅灰色区域),严重影响滤波精度. 因此,如何改进粒子滤波的重采样策略,增加粒子多样性以使后验分布的高概率区被尽可能覆盖,是提高粒子滤波估计精度的一个关键问题.

图1重采样示意图
Fig.1Resampling illustration
3 混合自适应重采样的粒子滤波方法
为解决传统重采样引起的粒子多样性匮乏问题,本文在自适应M-H采样的机制下,提出了高斯变异的自适应协方差矩阵计算函数,将改进后的高斯变异与自适应交叉算子相结合,并改进了接受拒绝准则和有效粒子集合更新方式,进而提出一种混合自适应智能重采样方法. 与传统重采样方法相比,该方法不再直接采用复制高权值粒子取代低权值粒子的策略,避免了重采样后的粒子集合中出现大量相同的粒子,抑制了粒子多样性匮乏的问题. 同时该策略可以根据粒子分布情况自适应调整,能够有效的自适应覆盖后验概率分布的空高概率区,进而优化了粒子分布,提高粒子重采样质量和粒子滤波的估计精度. 在新粒子产生以后,权值高的新粒子能够保证被接受并实时补充到高权值粒子集合中,避免当高权值粒子数量较少时,个别粒子被多次重复抽取导致新粒子分布过于集中到狭窄的高概率区.
3.1 自适应M-H重采样机制
为提高粒子集合的整体质量和覆盖后验概率分布的高概率区,本文改进了自适应M-H重采样机制. 首先对从重要性概率密度抽取的粒子进行降序排列,并根据下式将其划分为高权值粒子集合 XH 和低权值粒子集合XL,即
(8)
式中: 权值阈值WT = W(⌈Neff⌉),⌈·⌉表示向上取整; W为降序排列后的权值集合; Neff为有效样本数量,可根据下式计算:
(9)
XH中的粒子均为高权值,将其视为有效粒子全部保留, XL中的粒子权值都较低,对该集合粒子进行重新采样,以优化粒子分布. 在对低权值粒子集合XL进行重采样时,本文使用自适应M-H抽样方法. 以概率λ(0 <λ <1)选择自适应高斯变异策略,以1 − λ的概率选择交叉策略. λ根据下式计算:
(10)
由式(10)可得,λ由低权值粒子数量占所有粒子数量的比例决定. 低权值粒子越多,λ越大,选择高斯变异的概率就越大,有利于增加高权值粒子的数量; 相反,高权值粒子越多,λ越小,选择交叉算子的概率就越大. 由于交叉算子是通过高低权值粒子进行交叉实现,更容易产生权值介于高权值粒子和低权值粒子之间的粒子,有利于改善低权值粒子的质量. 因此,该自适应M-H抽样方法有利于提高粒子集合的整体质量和覆盖后验概率分布的高概率区.
3.2 自适应高斯变异重采样策略
根据图1可得,在高权值粒子附近可能会存在一些空白的高概率区域,所以在高权值粒子周围抽取新粒子取代低权值粒子,可驱使低权值粒子向这些高概率区运动,以填补这些空白的高概率区域. 自适应高斯变异的主要思想是采用随机游走策略,从高权值粒子集合XH中随机抽取一个粒子并根据下式进行高斯变异:
(11)
式中:为高斯变异后的粒子,j ∈ {1,2,· · ·,NL},NL为低权值粒子集合XL中的粒子个数; 为变异前的粒子,l ∈ {1,2,· · ·,NH},为高权值粒子集合XH 的粒子个数; µ为均值向量且为协方差矩阵.
由式(11)可得,协方差矩阵直接决定高斯变异抽取新粒子的范围,设置合适的对抽取到高质量粒子具有重要影响.越大,随机采样的区域越大,但随机采样区域过大会导致粒子跳出后验概率分布的高概率区,使高斯变异丧失了应有的作用,尤其是当后验概率分布为多峰时,对高斯变异抽取的粒子质量影响更为严重. 因此,如何确定高斯变异的协方差矩阵成为核心问题. 本文提出根据粒子分布自适应调整协方差矩阵的方法,利用两两粒子之间的欧式距离建立自适应协方差矩阵函数,再利用该自适应协方差矩阵函数确定. 自适应协方差矩阵可根据下式计算:
(12)
式中: m为粒子的维度,I为单位矩阵,为在高权值粒子集合XH中距离被抽到粒子最近的一个粒子, n可根据下式确定:
(13)
由自适应协方差矩阵计算可得,本文提出的自适应高斯变异策略能够根据高权值粒子集合中的粒子分布自适应调整高权值粒子抽取范围,可有效避免抽取的新粒子远离高概率区,进一步提高抽取粒子的质量,从而提高粒子滤波的精度.
3.3 自适应交叉重采样策略
由于粒子退化现象的存在,经过多次迭代以后粒子集合两极分化较为严重, XH和XL两个集合中的粒子权值相差较大. 根据前面设计的自适应选择策略,当XH中粒子数量偏多时,为增加粒子多样性和提高整个粒子集合对后验概率分布的覆盖程度,采用交叉策略产生介于高权值粒子集合和低权值粒子集合之间的中间权值粒子.
自适应交叉重采样策略的思想来源于遗传算法中的交叉算子,该策略随机从高权值粒子集合XH中抽取一个粒子与当前被采样的低权值粒子交叉,实质上是在高权值粒子区和低权值粒子区之间的区域进行采样,从而提高了粒子集合的整体质量和粒子多样性. 自适应交叉重采样后的粒子可根据下式计算得到:
(14)
式中:为交叉后的粒子,j ∈ {1,2,· · ·,NL},NL 为低权值粒子集的粒子个数; 为高权值粒子集的粒子,l ∈ {1,2,· · ·,NH},NH 为高权值粒子集的粒子个数; 随机数αj ∼ U(0,)为交叉率,可根据下式计算:
(15)
由式(14)–(15)可得,αj决定了新产生粒子中包含的高、低权值粒子信息占比,表示高权值粒子占所有粒子的比例. 当前粒子集合中高权值粒子数量较多时,较大,粒子交叉时选用的低权值粒子信息更多,以促使粒子位于中概率区的尾部; 当前粒子集合中高权值粒子数量较少时,较小,粒子交叉时选用的高权值粒子信息更多,保证新产生的粒子位于高概率区. 自适应交叉重采样策略可根据当前粒子集合的分布情况,自适应调整交叉过程中父代高低权值粒子遗传至新粒子的信息占比,从而提高整个粒子集合的质量和粒子滤波的精度.
3.4 接受拒绝准则
根据接受拒绝准则函数更新粒子集是M-H重采样方法的核心步骤. 利用两种重采样策略产生新粒子后,需对新粒子进行评估,确定是否接受该粒子. 原有的接受拒绝准则函数如下式所示 [21] :
(16)
式中:为粒子归一化之前的权值,为粒子归一化之前的权值.
由式(16)可知,接受概率与有关,根据M-H抽样方法的接受拒绝原理,以接受率为的概率接受M-H重采样后的新粒子此接受拒绝准则函数具有两个缺点: 一个是需要计算新粒子与原低权值粒子的权值比值和产生随机数,不利于提高重采样的实时性; 另一个是即使新粒子的权值低于原粒子也可能以低概率被接收,这严重影响了重采样后的粒子质量和重采样效率.
为此,本文对接受拒绝函数进行简化,不再通过计算新粒子与原粒子的权值之比和产生随机数以概率形式接受拒绝新粒子,而是采用“优胜劣汰”的方式直接将两个粒子的权值进行比较,确定性地接受或拒绝新粒子. 改进后的接受拒绝函数如下式所示:
(17)
式中为重采样后经过接受拒绝后的粒子.
由式(17)可得,本文改进的接受拒绝函数省略了计算权值比值和产生随机数的步骤,减少了算法的运算时间,保证了更优秀的粒子被接受和更差的粒子被淘汰,可进一步提高重采样后粒子集合的整体质量并提高粒子滤波的精度.
3.5 粒子集更新方法
原来的粒子集更新方式为将接受后的新粒子放入一个独立的粒子集合XS中,然后再对下一个低权值粒子进行重采样,直到当j = NL时,完成对低权值粒子集合XL中所有粒子的重采样,而重采样后的粒子全部都放在粒子集合XS中,最后将XS 与XH合并得到新的粒子集合. 这种方法一个典型的缺陷就是在对下一个粒子进行重采样时并未用到新产生的高权值粒子信息,当高权值粒子集合中的粒子数量较少时,个别高权值粒子存在被反复抽取的可能,尤其是在高斯变异时,产生的新粒子会聚集在被抽取粒子周围的狭窄区域,导致其它高概率区未被有效覆盖,造成粒子多样性未能有效提高从而影响粒子滤波的估计精度.
因此,本文提出对高权值粒子集合进行实时更新的方法,即在每次新粒子被接受以后,将直接放入高权值粒子集合XH中,当对下一个低权值粒子进行重采样时,新产生的高权值粒子就有可能被抽到. 随着新粒子不断被放入高权值粒子集合XH中,XH包含的高权值粒子信息越来越丰富,粒子多样性被进一步提高,同时新粒子的覆盖范围也不断扩大,提高了粒子对高概率区的覆盖程度,进一步提高了粒子滤波的估计精度.
3.6 算法步骤
结合本文所提出的混合自适应重采样策略,得到智能粒子滤波算法步骤如下:
步骤 1 从先验分布p(x0)中抽取N个初始粒子;
步骤 2 从重要性概率密度函数中抽取粒子,根据式(7)计算粒子权值,并对权值归一化处理,得到粒子集合
步骤 3 将粒子集合根据式(8)分为高权值粒子集合XH和低权值粒子集合XL,对高权值粒子集合进行保留,对低权值粒子集合中的每一个粒子根据步骤4―7进行重采样;
步骤 4 产生一个随机数r ∈ [0,1],当执行步骤5,否则转到步骤6;
步骤 5 根据式(11)以自适应高斯变异策略产生粒子并计算权值;
步骤 6 根据式(14)以自适应交叉策略产生粒子;
步骤 7 根据式(17)对新产生的粒子进行接受或拒绝,得到粒子;
步骤 8 将新粒子放入高权值粒子集合XH,得到新的粒子集当重采样粒子数小于NL时,转到步骤4,否则转到步骤9;
步骤 9 根据式(6)计算最终的状态估计值.
4 实验及结果分析
为验证所提方法的有效性,本文设计了3个仿真实验,并引入基于萤火虫优化的粒子滤波(firefly algorithm intelligence optimized PF,FAIOPF)和自适应M-H 重采样智能粒子滤波(adaptive M-H resampling intelligent PF,AMHRIPF)作为对比算法 [13,20],每个实验独立重复运行100次. 第1个仿真选用一维非平稳经济增长数学模型,第2个仿真选用一维非线性单变量时间序列模型,第3个仿真选用雷达跟踪蛇形机动反舰导弹模型. 由于这3个模型具有很强的非线性,被广泛用于验证粒子滤波的有效性 [13,22-23] . 为对本文方法的性能进行定量评估,3个实验均选用均方根误差(root mean square error,RMSE)和平均绝对误差(mean absolute error,MAE)作为评价指标.
RMSE和MAE分别根据下式计算:
(18)
(19)
式中: K为蒙特卡洛实验次数,L为时间序列长度,分别为第i次独立重复实验中k时刻状态的估计值和真实值.
4.1 一维非平稳经济增长数学模型
由于该模型具有强非线性和双峰的特点,对其进行状态估计具有较高的难度,所以被广泛应用于验证粒子滤波的有效性 [22] . 它的系统模型描述如下:
(20)
(21)
式中分别为过程噪声和观测噪声.
在本次仿真中,过程噪声方差和观测噪声方差均为1,状态初值x0为0.1,时间序列长度L为100.3种算法的状态初值x0均设置为0.1,粒子数为100,FAIOPF和AMHRIPF两种算法的参数与参考文献一致.
表1为分别使用3种方法对一维非平稳经济增长数学模型进行100次独立重复实验的结果. 由表1可得,FAIOPF的RMSE和MAE始终都最大,AMHRIPF略小于FAIOPF,本文方法的RMSE和MAE最小. 图2和图3分别为3种方法对一维非平稳经济增长数学模型的状态估计追踪图和RMSE对比图. 由图2和图3可得,3种方法均能较好地对状态结果进行跟踪,但本文方法的RMSE几乎都小于其他两种方法. 由上述实验结果可得本文方法具有较高的估计精度和较好的稳定性.
表1模型4.1估计结果的RMSE,MAE
Table1The RMSE and MAE of the estimation results for the model4.1


图2模型4.1状态估计结果对比图
Fig.2Comparison of state estimation results for model4.1

图3模型4.1状态估计RMSE对比图
Fig.3RMSE comparison of state estimation for model4.1
4.2 一维非线性单变量时间序列模型
一维非线性单变量时间序列模型由于其具有较强的非线性,也被用于验证粒子滤波的有效性 [23] . 该模型的过程方程和观测方程描述如下:
(22)
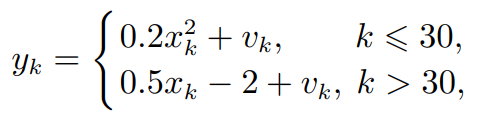
(23)
式中分别为过程噪声和观测噪声.
在本次仿真中,仿真模型的参数设置和3种算法的参数设置均与实验1一致.
图4和图5分别为3种方法对一维非线性单变量时间序列模型的状态估计追踪图和RMSE 对比图. 由图4可得,3种方法的状态估计值基本都在真实值附近. 由图5可得,FAIOPF的 RMSE较大,本文方法略小于 AMHRIPF.

图4模型4.2状态估计结果对比图
Fig.4Comparison of state estimation results for model4.2

图5模型4.2状态估计RMSE对比图
Fig.5RMSE comparison of state estimation for model4.2
表2为3种方法对一维非线性单变量时间序列模型100次独立重复实验估计结果的RMSE和MAE.
表2模型4.2估计结果的RMSE和MAE
Table2The RMSE and MAE of the estimation results for the model4.2

由表2可得,本文方法的MAE和RMSE均小于其它两种方法. 因此,本文方法对一维非线性单变量时间序列模型的状态估计精度要优于其他两种方法,具有更强的稳定性和更高的滤波精度.
4.3 雷达跟踪蛇形机动反舰导弹模型
雷达跟踪蛇形机动反舰导弹模型是一个典型的高维非线性系统,其对状态估计算法的估计性能提出了更高的要求,因此,该模型被很多文献用于验证粒子滤波的有效性 [13] . 雷达跟踪蛇形机动反舰导弹模型的状态方程为如下式:
(24)
(25)
式中:
x(k)=[x(k)y(k) x ′(k)y ′(k)x ′′(k)y ′′(k)]T. x(k)为目标状态矢量,目标状态矢量中的分量分别代表水平位置、垂直位置、水平速度、垂直速度、水平加速度和垂直加速度; z(k)为观测值,过程噪声为w(k)∼ N(0,Qw),观测噪声为和分别表示过程噪声和观测噪声的协方差矩阵,且I2表示一个2×2的单位矩阵,ϖ 为机动频率.
在本次仿真实验中,的初始状态x0 = [60000 50 1450 0 0 − 50 × ϖ2 ] T,机动频率ϖ = 0.2 × π,采样周期T = 0.1 s,仿真步长 L= 400,粒子数N = 100. FAIOPF和AMHRIPF两种算法的参数与参考文献一致.
图6为3种方法对雷达跟踪蛇形机动反舰导弹模型的位置跟踪结果,图7分别为3种方法对雷达跟踪蛇形机动反舰导弹模型估计结果的RMSE. 表3和表4分别为3种方法对雷达跟踪蛇形机动反舰导弹模型100次独立重复实验估计结果的RMSE和MAE.

图6模型4.3状态估计结果对比图
Fig.6Comparison of state estimation results for model4.3


图7模型4.3估计结果的RMSE对比图
Fig.7RMSE comparison of state estimation for model4.3
表3模型4.3估计结果的RMSE
Table3RMSE comparison of state estimation for model4.3

表4模型4.3估计结果的MAE
Table4The MAE of the estimation results for the model4.3

由图6的跟踪轨迹可得,3种方法均能跟踪上真实轨迹. 但从局部放大的图形来看,FAIOPF误差较大,AMHRIPF的误差小于FAIOPF,本文方法的估计结果最接近真实值. 由图7可得,FAIOPF 的 RMSE 大于其他两种方法,而本文方法的RMSE小于AMHRIPF. 由表3和表4可得,本文方法对高维模型位置、速度、加速度估计结果的RMSE和MAE都最小,与FAIOPF和 AMHRIPF两种方法相比,本文方法对高维非线性系统同样具有较好的估计性能.
根据上述3个实验仿真结果的RMSE和MAE可得,本文方法对一维模型和高维模型的估计精度都优于现有算法.
5 结论
为抑制粒子多样性匮乏以提高粒子滤波的精度,本文提出了一种混合自适应重采样策略的智能粒子滤波方法. 该方法改进了M-H重采样机制,设计了高斯变异的自适应协方差矩阵计算函数,使得在高斯变异时能够根据高权值粒子的分布情况自适应抽取高权值粒子,进而提高高权值粒子的抽取质量和增加粒子多样性. 重新设计了接受拒绝准则和高权值粒子集合更新规则,保证高权值粒子能够被接受和高权值粒子集合中的高权值粒子信息实时更新. 最后,通过一维模型和高维模型对本文方法进行了仿真验证,实验结果表明本文方法可有效提高粒子的多样性,估计精度优于现有方法. 未来可将本文方法在更多不同类型的问题和数据集上进行验证,评估其鲁棒性和适用性. 如何进一步优化自适应协方差矩阵计算函数和重采样策略,使得重采样后的粒子更全面的覆盖后验分布的高概率区域以实现更准确的状态估计结果,是未来的研究方向和目标.