摘要
针对5G-R高速铁路越区切换使用固定切换阈值, 且忽略了同频干扰、乒乓切换等的影响, 导致越区切换成功率低的问题, 提出了一种玻尔兹曼优化Q-learning的越区切换控制算法. 首先, 设计了以列车位置– 动作为索引的Q表, 并综合考虑乒乓切换、误码率等构建Q-learning算法回报函数; 然后, 提出玻尔兹曼搜索策略优化动作选择, 以提高切换算法收敛性能; 最后, 综合考虑基站同频干扰的影响进行Q表更新, 得到切换判决参数, 从而控制切换执行. 仿真结果表明: 改进算法在不同运行速度和不同运行场景下, 较传统算法能有效提高切换成功率, 且满足无线通信服务质量QoS的要求.
关键词
Abstract
Aiming at the problem of using a fixed handover threshold for 5G-R high-speed railway cross section handover and ignoring the effects of same frequency interference and ping-pong handover, which leads to a low success rate of cross section handover, a cross section handover control algorithm based on Boltzmann optimized Q-learning is proposed. Firstly, a Q-table with train position action as the index was designed, and a Q-learning algorithm return function was constructed by comprehensively considering ping pong handover, bit error rate, and other factors. Then, a Boltzmann search strategy is proposed to optimize action selection and improve the convergence performance of the handover algorithm. Finally, taking into account the impact of co frequency interference of base stations, the Q-table is updated to obtain the handover decision parameters, thereby controlling the handover execution. The simulation results show that the improved algorithm can effectively enhance the handover success rate compared to traditional algorithms under different operating speeds and scenarios, and meet the Quality of Service (QoS) requirements of wireless communication systems.
Keywords
1 引言
目前,我国高速铁路使用 GSM-R(global system for mobile communications-railway)作为无线通信系统,但GSM-R为2G窄带系统,业务承载能力有限,已无法满足我国高速铁路高速率、低时延的数据传输要求. 随着5G 技术上升为国家战略,我国铁路无线通信系统将逐步从 GSM-R演进到第五代移动通信 5G-R(5G for railway)[1] . 在5G-R高速铁路场景中,列车运行速度将大幅提升,越区切换愈加频繁. 越区切换作为铁路移动通信系统的关键技术,对完成通信业务、保障高铁安全运行起着关键的作用 [2] . 目前,高速铁路越区切换一般选择固定切换阈值进行切换判决,已无法满足高速铁路发展的需求 [3],因此,如何提高切换成功率是目前研究的热点问题.
针对列车在高速运行过程中越区切换成功率低的问题,国内外学者开展了大量的研究工作. Qian等 [4] 提出了一种基于模糊逻辑控制的切换判决算法,选取接收信号强度、相对运动角度等参数进行优化,但该方法存在参数主观性难以量化的问题,影响切换性能. 陈永等 [5] 提出了一种基于长短期记忆循环神经网络的高速铁路越区切换算法,构建了基于长短期记忆网络(long short-term memory,LSTM)的越区切换迟滞门限参数动态预测深度学习网络,但存在未考虑相邻基站同频干扰的切换影响性问题. Zhu等 [6] 提出一种改进遗传算法的自适应联合判决切换算法,但初始化种群等参数对该算法的影响较大,导致算法性能受限. 王瑞峰等 [7] 提出基于位置信息与波束赋形辅助的切换算法,计算出预触发起点位置和触发位置,但存在未考虑切换影响因素的问题. Poolnisai 等 [8] 提出基于列车运行速度的动态切换算法,通过相邻基站间距和列车速度特征预先计算切换执行点,在预切换位置时发送切换请求并准备信道接入以执行切换. 马彬等 [9] 提出了基于高斯马尔可夫移动模型的切换优化算法,通过位置信息筛选出满足候选网络,但该算法难以适应高速动态运行场景. 孙志国等 [10] 提出了一种基于双门限判决的位置触发切换算法,但该算法存在门限取值单一的问题. 赵容瑢等 [11] 提出了基于卷积神经网络结合波形网络(convolutional neural network combined with WaveNet,CNN-WaveNet)的高铁无线通信越区切换算法,用卷积神经网络进行参数预测,该算法存在网络模型复杂的问题.
综上所述,现有算法对固定切换阈值难以适应列车速度提升的问题进行了改进. 但列车在切换过程中会受到同频干扰、乒乓切换等因素的影响 [12],导致切换效率低. 针对以上问题,本文提出了基于玻尔兹曼优化Q-learning的高速铁路越区切换算法. 在切换判决过程中考虑同频干扰、乒乓切换和误码率的影响,设计玻尔兹曼搜索策略进行动作选择,综合考虑Q值和同频干扰进行Q表更新,得到切换判决阈值,实现了切换成功率的提升.
2 基础理论
5 G-R的切换流程包含切换测量、切换判决和切换执行 [13] . 其中,切换判决是越区切换的核心,当网络执行切换判决时,切换参数直接影响切换性能. 根据第三代合作伙伴计划(3rd generation partnership project,3GPP)规定,切换参数包括: 参考信号接收功率(re-ference signal received power,RSRP)、迟滞门限参数(hysteresis,Hys)、触发时延参数(time-to-trigger,TTT)等 [14] . 切换判决示意图,如图1所示.

图1切换判决示意图
Fig.1Schematic diagram of handover decision
由图1可知,当待切换目标基站小区的RSRP与当前服务基站小区的RSRP的差值高于迟滞门限Hys,且在触发时延TTT内都满足上述条件时,触发切换判决. 切换判决表达式如下:
(1)
式中Mn,Ms分别为目标基站和源服务基站的信号接收功率. 由式(1)可知,切换阈值的选择是切换判决的关键,当切换算法选择合适的阈值时,能提升切换质量; 当切换阈值偏大或偏小时,则会出现切换失败、提前切换等问题.
3 改进Q-learning自适应切换算法
本文提出了基于玻尔兹曼优化Q-learning的高速铁路越区切换算法,综合考虑同频干扰、乒乓切换、误码率的影响,通过Q-learning算法动态调整切换阈值,以提高切换成功率. 本文将高铁越区切换问题建模为马尔可夫决策过程. 马尔可夫决策过程可以用以下四元组表示:(S,A,P,R)[9] . 智能体以当前状态si 在一定环境下以概率P从动作集A中选取动作ai,以进入下一状态si+1,并得到当前动作反馈的奖励R,进而更新Q表. 本文中状态集S由列车位置构成,动作集A由越区切换参数迟滞门限和触发时延的组合构成. 本文算法通过不断地迭代学习,使得Q表不断更新,通过模型训练,得到Q表回报的最大值,此值对应列车在当前位置的最优切换阈值组合,即得到当前位置下的切换迟滞门限和触发时延,并进行切换判决. 本文算法的主要步骤如下:
步骤 1 建立Q表. 以列车位置–动作为索引建立 Q表;
步骤 2 设计Q-learning算法回报函数. 将越区切换过程中的乒乓切换率、误码率和切换成功率作为回报函数参数;
步骤 3 改进动作选择策略.改进传统Q-learning 算法使用ε–贪心策略后期收敛性不足的问题,使用玻尔兹曼搜索策略,提高算法搜索的有效性;
步骤 4 设计算法Q表更新. 综合考虑Q值和同频干扰进行Q表更新,得到切换判决阈值;
步骤 5 执行切换. 根据算法推荐的切换迟滞门限和触发时延进行切换判决,完成越区切换.
3.1 Q表建立
传统Q-learning算法通过状态–动作建立Q表,即 Q(a,s),记录智能体从当前状态si以概率P从动作集A中选取动作ai,进入下一状态s 的回报值. 在越区切换场景中,需体现列车连续的位置信息,因此,本文算法建立Q表时考虑列车的位置信息,建立以列车位置–动作为索引的Q表. 在越区切换过程中,列车与基站之间的距离是进行切换判决的基础,列车与基站的位置关系如图2所示.

图2列车与基站的位置关系
Fig.2Positional relationship between trains and base stations
由图2所示,列车与基站之间的关系如下:
(2)
其中: x0为列车的初始位置,v为列车运行速度,t为切换测量时间间隔,dv为gNodeB与铁轨之间的垂直距离,列车和gNodeB的天线高度分别为hm和hb,由此获得列车的位置信息. 根据式(2)得到源基站到目标基站之间的位置数据,构成位置集D{d1,d2,· · ·,dn}. 此外,切换判决过程包含两个重要参数: 迟滞门限 Hys和触发时延TTT,迟滞门限为评价目标基站信号质量好坏的基础和门槛,触发时延起到延缓切换事件进入或退出的作用,以提高判决的可靠性,因此将迟滞门限和触发时延的组合作为动作a,即a(Hys,TTT),构成动作集A{a1,a2,· · ·,an}. 由此建立列车位置– 动作为索引的Q表,即Q(d,a).
3.2 回报函数设计
完成Q表建立后,进行回报函数设计. 回报函数R 代表环境给智能体的反馈,反映智能体执行动作的好坏. 在5G-R越区切换过程中,列车行驶至信号重叠区时,由于源基站和目标基站的信号强度大小相仿,列车易在两基站之间来回切换,发生乒乓切换,存在算法稳定性差的问题 [13] . 此外,随着列车远离源基站,源服务基站信号强度降低,信号干扰增加,导致使误码率增加,影响通信质量. 因此,本文将乒乓切换率 Pppho、误码率BER作和切换成功率 Psucc 设置为 Qlearning算法回报函数参数. 其中,乒乓切换率为列车成功切换至目标基站后又切换到源基站的次数与总切换次数中的比值,乒乓切换率Pppho的计算公式如下:
(3)
式中: Nppho(d)为发生乒乓切换的总次数; Nsucc_ho(d)为成功切换的总次数; Nfail_ho(d)为发生切换失败的总次数. 误码率表示信号传输的可靠性,为信号强度与信号同频干扰的比值,误码率BER的计算公式如下:
(4)
式中: Q(x)为正态分布右尾函数; Pr(d)为信号强度; I(d)为信号干扰. 切换成功率是衡量越区切换性能的关键指标,通过切换过程中的切换判决触发概率和切换执行概率进行求解,切换成功率Psucc的计算公式如下:
(5)
式中: Ptrig(d,a)为位置为d 动作为 a 时的切换触发概率; Pexe(d,a)为位置为d 动作为a 时的切换执行概率. 综合考虑以上影响因素,本文采用加权求和的方式建立回报函数,回报函数建立如下:
(6)
式中ωp,ωB,ωs分别表示乒乓切换率、误码率、切换成功率的客观权重.
3.3 动作选择策略设计
在完成回报函数建立后,下一步进行动作选择策略设计. 传统Q-learning算法选择ε-贪心策略作为动作选择策略,引入探索因子ε平衡算法中随机动作和贪婪动作的选择,公式描述如下:
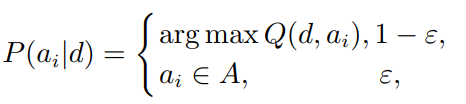
(7)
式中: ai表示在位置d下执行的动作; Q(d,ai)为在位置d 采取动作ai的Q值. 该搜索策略的存在难以找到合适的探索因子ε的问题. 当探索因子ε取值过小时,搜索策略易陷入局部最优; 当探索因子ε取值过大时,搜索策略更偏向于探索,导致算法收敛性差 [15] .
本文提出玻尔兹曼(Boltzmann)采样作为搜索优化策略,进行切换动作选择. 所提Boltzmann策略,其具体表达式如下:
(8)
(9)
式(8)中, T为温度参数; 式(9)中: λ为折扣因子,T0为初始温度参数,k为算法迭代次数. 在Boltzmann采样中,温度参数T控制动作选择的探索程度. 在算法前期,该搜素策略允许智能体在选择动作时,考虑选择所有可能的动作,使搜索策略在迭代前期侧重于探索; 随着迭代过程的进行,T值减小,通过选择奖励值大的动作,使搜索策略重于利用,以提高算法的收敛性.
3.4 Q表更新方式设计
接着进行Q表更新设计,传统Q-learning算法中,智能体仅通过回报函数R计算此状态si下选取动作 ai的回报值ri+1,并转移到下一个状态si+1,并更新 Q表 [16] . 如式(10)所示:
(10)
式中: α为学习率,表示算法更新幅度的大小及训练时间的长短,α越大则算法更新幅度大且训练速度快,α越小则学习速度较慢但更稳定; γ为折扣因子,表示在当前动作下智能体对将来产生影响的重视程度,γ越小表示重视当前收益,γ 越大表示重视长远收益.
但在5G-R越区切换过程中,列车极易受到相邻基站的同频干扰的影响,因此本文算法提出将同频干扰与回报值相结合的Q表更新方法. 当智能体在下一时刻位置进行Q 表更新时,综合考虑智能体在当前位置节点与下一位置节点之间的Q值与列车在当前位置节点受到的同频干扰大小来进行行为决策. 列车在位置d受到的同频干扰计算公式如下 [17] :
(11)
式中Pr1,Pr2为同频基站信号强度. 同频干扰大小如图3所示.
由图3可知,列车在基站信号重叠区中间位置时,同频干扰值最小,随着靠近目标基站,受到目标基站附近的同频基站的信号干扰增大,降低列车通信质量,影响越区切换. 因此本文考虑同频干扰因素,通过判断列车在当前所处的位置,选取Q表中该位置对应的最大Q值的动作. 依据该动作选取5G-R切换阈值参数组合,通过新的参数更新智能体的信息,计算更新过程得到的奖励,结合智能体新的位置和动作对Q表进行更新. 考虑越区切换同频干扰影响的列车位置–动作Q表更新公式如下:
(12)
式中: I(d)为列车在位置d受到的同频干扰; a为当前状态下可选择的动作.

图3同频干扰
Fig.3Co-frequency interference
3.5 执行切换
Q-learning算法每轮迭代会对Q表进行更新,直至算法收敛后得到训练后的Q 表. 在该 Q表中根据最大Q 值可获得列车在不同位置下的最优动作组合 a(Hys,TTT),输出此组合即为最优切换阈值组合,即得到列车在不同位置下的最优迟滞门限Hys和触发时延TTT. 在得到越区切换判决参数之后,需要将迟滞门限Hys 和触发时延 TTT参数预测结果送入切换判决 [18] . 在越区切换场景中通过A3事件进行切换判决,即根据目标基站小区 RSRP与当前服务基站小区 RSRP差值与迟滞门限 Hys进行比较. 若在触发时延 TTT内,该差值均高于迟滞门限Hys,则完成切换判决,列车断开与现有小区基站的连接,建立与目标小区基站的通信,从而完成越区切换.
4 仿真分析
4.1 参数设计
本文采用栅格法创建列车位置–动作Q表,栅格横轴表示列车位置,通过测量报告获取源基站到驶出相邻基站重叠区间的位置信息,其间距为3km. 纵轴表示由迟滞门限和触发时延组合构成的动作集合,根据3GPP规定,本实验中迟滞门限取值为1∼10dB; 触发时延的取值为100 ms,128 ms,160 ms,320 ms,512 ms,640 ms [19] . 由此构成60个动作集合. 在构建回报函数时,通过 CRITIC 权重法 [20] 计算的权重值 ωp,ωB,ωs为[0.057 0.045 0.898],参数设置如表1所示 [6] .
4.2 仿真实验
其次,以常规列车运行速度 50 km/h,150 km/h 和 350 km/h,450 km/h分别代表低速和高速场景,进行算法训练,得到列车位置–动作Q表训练值,低速场景实验结果和高速场景实验结果分别如图4和图5所示. 在图4中,纵轴表示动作,由切换判决中的重要参数触发时延TTT和迟滞门限Hys的组合构成. 纵轴数值从下到上依次递增. 从训练结果可以看出,蓝色和绿色区域Q表训练值较小,红色区域Q表训练值最大,即在红色区域内的动作值能获得回报值. 由红色区域内的动作可以得到算法推荐的切换阈值. 当列车速度为 50 km/h 时,红色区域为集中在Q表训练值的第41– 50行,即得到推荐触发时延为512 ms; 同理可得列车速度为150 km/h时,推荐触发时延为 320 ms. 由此可知,通过本文算法得到的触发时延随着列车运行速度的增大而减小,这是因为减小触发时延可以及时触发切换,提升列车响应切换的速度 [6] . 此外,由图4可知,随着列车运行速度的提升,红色区域逐渐增大. 这表明本文算法能以较小的切换干扰得到较高切换成功率,证明本文算法动态调整切换阈值的有效性.
表1仿真参数设置
Table1Simulation parameter settings


图4低速Q表训练值
Fig.4Low speed Q-table training value

图5高速Q表训练值
Fig.5High speed Q-table training value
图5为高速环境下的实验结果,横轴表示列车位置信息,从左到右,列车逐渐远离源基站. 由图5可知,随着横坐标的增大,Q表训练值先逐渐增大,后减小. 这是因为列车刚驶过源基站时,列车接收到的目标基站信号强度较低,无法触发切换,Q 表训练值保持较小值. 随着列车行驶至切换重叠区,目标基站信号强度逐渐增加,训练值有所增加,但在此位置由于受到乒乓切换的影响 [21],Q 表值并没有达到最大. 随着列车继续靠近目标基站,Q表值明显增大,这是因为目标基站的信号强度继续增大,信号稳定,易触发切换事件,切换成功率高,因此Q表值达到最大,推荐切换. Q表值后续出现降低是因为列车靠近目标基站,受到目标基站附近同频基站的影响,通信质量下降,影响切换.
为进一步分析本文方法的有效性,根据列车在不同运行速度下的Q表训练值,获取列车距源基站的距离值和切换阈值,结果如表2所示.
由表2可知,当列车运行速度增大,本文算法触发时延和迟滞门均减小,该趋势符合当列车速度增大,为保证列车在信号重叠区及时完成切换,应减小切换阈值的规律 [6],进一步验证了本文所提方法的有效性. 此外,从算法推荐的切换位置中可以看出,随着列车运行速度的提升,切换位置更靠近源基站,这是因为在切换判决时,切换阈值减小,易触发切换事件,保证了列车在高速条件下完成切换,避免了切换不及时导致的安全问题. 为验证本文算法的有效性,与传统切换算法、文献 [22] 基于模糊逻辑优化的越区切换算法、文献 [11] 基于CNN-WaveNet算法的切换算法进行切换成功率的比较,结果如图6所示.
表2列车位置、切换阈值
Table2Handover position, handover threshold


图6切换成功率比较
Fig.6Comparison of handover success rates
由图6可知,在切换成功率方面,本文 Q-learning 较对比算法切换成功率最高. 传统A3切换算法使用固定切换阈值,无法实现自适应调节切换阈值,因此在列车在高速行驶时,存在由于切换阈值过大而切换不及时的情况,导致切换成功率低 [5] . 文献 [22] 算法得益于根据输入的数据进行模糊处理实现调整阈值,较传统切换方法有效提高切换成功率,但模糊处理导致切换成功率控制的精确度降低,继而出现切换成功率振荡的现象. 文献 [11] 算法通过卷积神经网络能有效提取判决参数时序特征,较传统切换算法能有效提高切换成功率,但该算法未考虑同频基站之间的信号干扰,随着列车运行速度的提升,切换成功率均低于本文算法. 本文Q-learning算法表现优秀,在列车运行速度不断增大的过程中,切换成功率均大于99.5%,满足我国高速铁路无线通信系统服务质量QoS对于越区切换要求功率不低于99.5%的要求 [23],证明了本文方法的有效性.
最后,进一步得到列车在不同高铁场景下的切换成功率比较实验,比较结果如图7所示.

图7不同速度下切换成功率的比较
Fig.7Comparison of handover success rates at different speeds
由图7可知,在相同运行速度下,开阔地场景切换成功率高于城区场景下的成功率. 这是因为在开阔地场景下,地势平坦、遮挡少,列车接收信号稳定,所以切换成功率高. 而城区场景建筑物密集,信号衰落严重,因此其切换成功率最低. 综合上述切换成功率实验可以发现: 采用本文方法得到的切换成功率均高于99.5%,均能满足高速铁路切换成功率要求,从而进一步验证了本文方法的有效性.
5 结论
5 G-R是我国下一代高速铁路无线通信系统,针对 5G-R无线通信系统越区切换算法使用固定阈值,无法在高速环境下及时完成切换,本文提出了一种基于玻尔兹曼优化 Q-learning的高速铁路越区切换算法,得出以下结论:
1)根据列车位置–动作建立Q表,综合考虑切换过程中乒乓切换、误码率等对切换的影响设计了回报函数,克服了传统切换判决算法考虑因素单一的不足;
2)提出了将玻尔兹曼搜索策略作为算法动作选择策略,改进动作选择策略,提高了越区切换算法的收敛性能;
3)仿真表明,所提方法在不同列车运行速度下,以及不同高铁运行场景下,均能有效提高越区切换的成功率,能够满足我国下一代 5G-R无线通信系统QoS切换成功率要求.