摘要
现有的基于学习的构造任务分配方法需要在连续构造一个完整任务分配方案后, 再将任务分配给智能体去执行, 其在救援、对抗等大规模紧急任务场景下通常无法满足任务的实时性需求. 本文则针对大规模紧急任务场景下异构多智能体任务分配策略寻优问题, 提出了一种基于深度强化学习的多智能体批次任务分配方法. 在该方法中设计了包含编码器、智能体和任务节点选择解码器、递归嵌入结构的策略模型, 其能够根据目标函数的最优性要求一次给出一个批次的由智能体–任务节点对所构造的部分任务分配方案. 在在线任务分配中相应的智能体不用等到构造完完整的任务分配方案后再去执行相应的任务. 评估结果表明, 多智能体批次任务分配方法提高了紧急任务场景下任务分配策略的实时性、可靠性和协同能力.
Abstract
Existing learning-based constructive task allocation methods require continuously generating a complete task allocation scheme before assigning tasks to agents, which fails to meet the real-time demands of large-scale urgent scenarios such as rescue or confrontation. To address this, a multi-agent batch task allocation method based on deep reinforcement learning is proposed in this paper. In this method, a policy model including an encoder, agent and task-node selection decoders, and a recursive embedding structure is designed that can generate a batch of partial task allocation schemes constructed by agent-task node pairs simultaneously according to the objective function’s optimality requirements. In online task allocation, agents no longer need to wait for the complete task allocation scheme before executing the tasks. The evaluation results showed that the proposed method improves the real-time performance, reliability, and cooperative capability of task allocation in urgent scenarios.
1 引言
随着人工智能技术的不断发展,无人系统在各个领域也逐步取得了广泛的应用 [1-2],多智能体任务分配技术在多无人系统执行各种复杂任务中起到了关键的作用 [3] . 尽管基于学习的任务分配方法 [2,4] 相比于基于传统启发式的任务分配方法 [5] 具有更强的实时性,但在救援、对抗等大规模紧急任务场景下的任务分配中,基于学习的任务分配方法仍然存在实时性不足的问题 [6] . 因此,本文针对大规模紧急任务场景下异构多智能体任务分配问题,提出了一种基于深度强化学习的多智能体批次任务分配方法(multi-agent batch task allocation,MBTA).
基于学习的任务分配方法的本质是通过从大量训练数据集中发现潜在的模式来自动学习待求解问题的搜索规则 [7-13] . 由于基于学习的任务分配方法通常具有更强的泛化能力和实时性 [13],近几年在对抗任务分配 [14] 和应急救援场景下的资源调度问题中广泛采用了基于学习的任务分配方法 [15] . 此外,通常将基于学习的任务分配方法分为构造方法(construction method)和递进方法(improvement method)两类 [12] .
构造方法从待求解问题的一个空解开始依次将每个任务分配给一个智能体,在所有任务都被分配完毕后才构造成完整的分配方案. 并且,通常只通过深度模型解码器选择任务节点 [9,13,16] . 比如,在一种多星应急任务规划方法 [4] 以及一种基于Transformer的森林救火无人机任务分配方法中,就只利用Transformer 解码器来选择要执行的任务 [15] . 递进方法从待求解问题的一个完整初始解开始,选择待分配的任务或启发式运算符,或两者都选择,以在每一步都改进和更新解决方案.
然而,基于学习的任务分配方法仍有待进一步完善. 递进方法在寻找高质量任务分配方案和可扩展性方面存在不足,在一定程度上限制了其应用 [17] . 构造方法 [18] 在线求解任务分配方案时需要重复运行模型,从而给出一个完整的分配方案 [9,19],对于紧急任务场景下的大规模任务分配问题,在线构造一个完整分配方案需要的时间通常过长 [1-2] .
本文针对紧急任务场景下的大规模任务分配问题,提出了一种多智能体批次任务分配方法(MBTA). 在一个批次任务分配中,递归嵌入结构能够使智能体选择解码器和任务节点选择解码器可以重复选择智能体和任务节点,进而构造一个部分任务分配方案,提高了任务分配的实时性. 此外,在一个新批次的任务分配中,MBTA会重新对状态进行编码,使批次任务分配方法在紧急任务场景中具有更强的可靠性. 并且,MBTA还能给出让智能体协同执行任务的分配方案.
2 问题描述和背景知识
本文以无人机执行对抗任务、无人车执行夺控任务以及无人通信车执行通信中继任务为基本想定,将这些无人系统视为智能体并研究多智能体任务分配问题. 假设所有智能体都从一个基地出发,且可以返回基地补给,且对抗任务和夺控任务分别可能需要多架无人机或多辆无人车来执行.
2.1 多类型任务分配数学描述
假设有n个待分配的任务,用于执行任务的无人机、无人车和无人通信车的数量为 m. 定义 = [] T (i ∈ T = {1,2,· · ·, n})表示任务i在 t时刻的表征,其中: [·] T表示转置操作; p i∈表示任务i的二维位置; e i ∈ Te = {Ta,Ts,Tc} = {1,2,3}表示任务i的类型,Ta,Ts和Tc分别表示对抗任务、夺控任务和通信中继任务; 表示任务 i在t时刻的紧急程度; ∈ 表示任务 i在t时刻的能力需求. (ν ∈ U ={1,2,· · ·,m}表示智能体ν的表征,其中: 表示智能体ν在t时刻的位置; u ν ∈ Uν = {Ua,Us,Uc} = {1,2,3}表示智能体ν 的类型,Ua,Us和Uc分别表示无人机、无人车和无人通信车; 表示智能体ν在t时刻的能力值. 对于执行通信中继任务的无人通信车,代表其通信能力的变量 是常量; 对于执行对抗任务的无人机和执行夺控任务的无人车, 分别表示无人机和无人车在t时刻的对抗能力值和夺控能力值. 当ei表示对抗任务或夺控任务时,这个任务可能分别需要多架无人机或多辆无人车来执行; 当e i表示通信中继任务时,则该任务只需一辆无人通信车来执行.
定义T + = T ∪ {0}表示包括返回基地的任务集合. 定义 mi,ν ∈ {0,1},bi,ν ∈ {0,1}和 ∈ {0,1}分别表示一个二进制变量,其中 = 1时表示智能体ν去执行任务 j,且执行任务 j 之前在执行任务 i. D(p i,pj)表示任务节点i到j的欧几里得距离,表示初始时刻任务i的紧急程度,s(·)表示单位阶跃函数. 在一个批次的任务分配方案中,多架无人机或无人车可以分别协同执行对抗任务或夺控任务. 因此,定义− 1表示在某一时刻任务 i被分配给 架无人机或辆无人车所获得的奖励. 在以上定义下,总路程代价函数为
(1)
总紧急程度代价函数为
(2)
总协同代价函数为
(3)
其中: ReLU(·)表示ReLU激活函数,Cl表示使fs(t)>0的一个给定常量.
在本文紧急任务场景想定下,总的代价函数分别包括总路程代价、总紧急程度代价和总协同代价,如下:
(4)
代价函数(4)需要满足的相关约束为
(5)
(6)
(7)
(8)
(9)
(10)
在本文的场景想定中,无人通信车在执行通信中继任务时不消耗自身的能力值. 约束(5)表示执行任务的智能体ν的类型与任务i的类型要互相匹配. 约束(6)表示智能体ν执行任务j之前正在执行任务i. 约束(7)和约束(8)确保在一次任务分配中,每个通信中继任务只分配给一辆无人通信车就能完成,并且相邻的通信中继任务是由同一辆无人通信车执行的. 约束(9)确保无人机或无人车在执行对抗任务或夺控任务之前和之后所具有的能力值之差等于对应任务的能力需求量. 约束(10)确保将最大化协同目标转化为代价函数的形式.
2.2 多类型任务分配强化学习描述
参考任务分配问题中常用的马尔科夫决策过程(Markov decision process,MDP)建模方法 [20],关于本文所讨论的任务分配问题的MDP元组的定义如下:
状态 S: 定义 xt = [] T表示所有任务在 t 时刻的矩阵,且定义 yt = [] T表示所有参与任务分配的智能体在t时刻的矩阵. 则定义t时刻任务分配问题的状态 st = [(xt) T(yt) T] T .
动作A: 定义本文任务分配中的动作为从集合U 中选择智能体ν和从集合 T 中选择任务 i,则at = [ν i] T . 此外,定义智能体的策略为π,且定义在状态 st下采取行动at的概率分布为π(at |st).
(11)
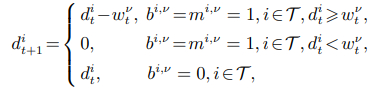
(12)
(13)
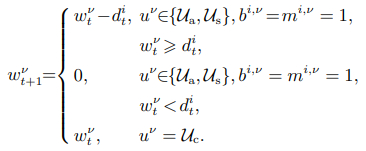
(14)
奖励函数rt : 根据式(4)所定义的代价函数,本文定义t时刻的奖励为该时刻代价函数的负值,即
(15)
3 多智能体批次任务分配
本文针对紧急任务场景下的大规模多类型任务分配问题,提出了一种多智能体批次任务分配方法 MBTA. 该方法避免了基于学习的任务分配中的构造方法在大规模任务分配中,在线构造一个完整的任务分配方案时间过长的缺点,提高了紧急任务场景下任务分配的实时性和可靠性. 此外,在MBTA的批次任务分配中还能给出让多智能体协同执行任务的分配方案.
3.1 MBTA及其策略网络模型构建
定义πθ(at |st)表示参数为θ的神经网络策略模型所给出的随机策略. 从初始状态s0开始,按照第2.2节所描述的MDP构造策略πθ,并且每隔一定步骤就会给出一个批次的任务分配方案. 在tf时刻,所有任务都被分配完毕,状态s0也转移到终止状态. 并且,每个批次的部分分配方案也能够构成完整的任务分配方案. 本文所设计的批次任务分配方法MBTA的简要原理示意图如图1所示,其中: Qh表示一个长度为h的队列,h表示给定的一个批次任务分配中智能体–任务节点对的个数; Ld表示用于训练策略模型的数据存储列表. 此外,MBTA的策略模型由编码器、智能体选择解码器、任务节点选择解码器和递归嵌入结构组成,其结构示意图如图2所示.
MBTA的简要工作流程如下:
1)利用编码器对状态st进行编码,得到实体编码和实体均值编码输出;
2)智能体选择解码器根据上一轮递归嵌入结构编码和编码器的输出特征信息生成选择智能体的对数概率,并依据该对数概率选择一个智能体ν,其中 表示选择智能体的动作;
3)任务节点选择解码器根据选择的智能体和编码器的输出特征信息生成选择任务节点的对数概率 ,并根据该对数概率选择一个任务i,其中表示选择任务节点的动作;
4)更新递归嵌入结构和状态st,并将
以一个列表的数据格式输入到队列Qh中,用于策略模型的学习;
5)判断队列Qh的长度是否等于h. 如果Qh的容量小于h,则返回智能体选择解码器开启新一轮的智能体和任务节点的选择; 如果Qh的容量等于h,返回编码器并重新对状态进行编码;
6)判断状态是否达到终止状态,如果到达终止状态,则利用Ld中存储的数据并使用Reinforce强化学习方法 [23] 优化该策略模型.

图1批次任务分配方法简要原理示意图
Fig.1Schematic diagram of the batch task allocation method

图2策略模型结构示意图
Fig.2Structure diagram of the policy model
3.1.1 编码器
编码器将第2.2节所定义的状态st的原始特征嵌入到更高维度的空间中,然后通过注意力层对其进行处理,以更好地提取特征. 在编码过程中,本文将状态st 中的任务节点特征和智能体特征 统一视为实体特征. 并采用与原始Transformer模型 [9,26] 中的编码器类似的结构,将实体特征线性投影到特征维度为de = 128 的高维空间中,得到节点特征. 然后,为了更好地提出到状态中的特征信息,通过N个注意力层将进一步变换为 . 其中,每个注意力层由一个多头注意力(multi-head attention,MHA)子层和一个前馈(feed forward,FF)子层组成.
第l个MHA子层使用一个多头自注意力网络来处理节点嵌入,并获得新的节点嵌入hl =( ). 本文定义 dk = de/Y 为查询(query)和键(key)的维度、dv = de/Y 为值(value)的维度,其中Y = 8为编码器中注意力层的头数. 第l个MHA子层首先计算每个头的注意力值Zl,y(y ∈ {1,2,· · ·,Y }),然后将所有这些头的输出拼接起来,并将它们投影到与输入hl具有相同维度的新特征空间,则利用多头注意力机制进行编码的具体过程为
(16)
(17)
(18)
其中:表示第l层的可训练参数,并且其在不同的注意层之间是相互独立的; Concat(·)表示对括号内的矩阵进行拼接操作.
将第l个MHA子层的输出输入到第l个具有ReLU 激活函数的 FF子层,得到下一个嵌入 hl+1. 其中,MHA和FF子层都使用了跳连接(skip-connection)[24] 和批归一化层 [25],即
(19)
(20)
其中BN(·)和FF(·)分别表示前馈操作和批归一化操作. 最终,根据编码器的计算过程,分别得到实体编码和实体均值编码
3.1.2 智能体选择解码器
智能体选择解码器以实体编码和上一轮更新后的递归嵌入编码为输入,并利用注意力机制通过指针网络 [16] 的形式选择执行任务的智能体. 由于本文将智能体特征和任务节点特征统一视为实体特征,在算法的实际执行过程中会设计相应的掩码以防止智能体选择解码器选择任务节点,同时也会根据式(5)–(10)所示的约束来设计相关的掩码.
首先,使用一维卷积对实体编码输出进行编码得到键值ke,如下所示:
(21)
其中conv1d(·)表示一维卷积操作.
然后,利用线性全连接层和一个参数规模较小的长短期记忆(long short-term memory,LSTM)[26] 网络生成注意力机制的查询值qe,如下所示:
(22)
其中: LSTM(·)表示神经网络中的LSTM操作; Ae表示上一轮更新后的递归嵌入编码; Ln (·)表示神经网络的线性全连接层(linear projection). 此外,在每一个批次任务的开始,将实体均值编码赋值给递归嵌入编码Ae.
最后,利用qe和ke生成选择智能体的对数概率,如下所示:
(23)
其中norm(·)表示Softmax归一化操作函数 [27] . 此外,根据智能体选择策略的概率分布选择执行任务的智能体ν ∈ U.
3.1.3 任务节点选择解码器
任务节点选择解码器以编码器的输出特征信息和智能体选择解码器选择的智能体ν作为输入,并利用注意力机制选择智能体ν要执行的任务.在算法的实际执行过程中会设计相应的掩码以防止任务节点选择解码器选择智能体,同时也会根据式(5)–(10)所示的约束来设计相关的掩码. 首先,定义一个上下文变量
(24)
其中,表示实体均值编码; 表示所选智能体ν在上一轮所执行任务的实体编码; 为在第2.1节中定义的智能体ν的剩余能力值. 该上下文向量突出了当前决策步骤中所选智能体的特征,并从全局角度考虑了所有实体特征 (i ∈ Me)的实体均值编码 .
然后,将上下文向量 和节点嵌入hN输入到一个MHA层中,以合成一个新的上下文向量 [12],如下所示:
(25)
其中 和 分别为可训练的参数.
最后,通过比较上下文 和节点嵌入hN之间的关系,生成选择任务节点的对数概率,如下所示:
(26)
其中:且和分别为可训练的参数,并设置系数 C = 10. 此外,根据任务节点选择策略的概率分布选择智能体ν要执行的任务的节点i ∈ T .
3.1.4 递归嵌入结构
本文设计的递归嵌入结构,能让智能体结合两部分信息选择执行任务的智能体: 一是本批次已选定的智能体–任务节点对信息,二是编码器的输出特征信息,且该选择过程需通过解码器完成. 这种设计使得智能体和任务节点选择解码器可以重复选择智能体和任务节点,从而构造一个部分任务分配方案. 定义o ν和oi分别为选择的智能体ν和任务节点i所对应的独热编码(one-hot encoding).
首先,对智能体选择解码器在计算过程中得到的键值ke在实体维度上求和并除以实体的数量得到
(27)
其中表示ke中关于实体i的部分.
然后,根据上一轮选择的智能体和任务节点对应的独热编码和,以及ke和计算递归嵌入编码Ae,其更新规则为
(28)
3.2 训练算法
采用具有rollout 基线的 Reinforce策略梯度方法来训练策略模型 πθ,并在训练过程中将和统一视为 (at | st). 定义损失函数为式(4)所示代价fc(tf)关于策略 πθ (at |st)的期望,即
(29)
该损失函数对应的策略梯度为
(30)
其中 为rollout基线. 为了以较简洁的方式获取 rollout基线,本文采用具有衰减系数β的指数移动平均基线
(31)
其中在第一次计算策略梯度时 = .
4 仿真实验与分析
为了充分评估MBTA的性能,设计了基于任务分配实例的模拟紧急任务场景下我方多智能体执行多类型任务的仿真实验,生成了相应的训练数据集和测试数据集,并使用测试数据集对正在训练的任务分配策略模型进行测试. 首先,在不同的参数配置下对MBTA的有效性进行充分的验证; 然后,将MBTA与现有的构造任务分配方法AttenTD [12] 进行对比评估. 表1给出了本文在数据集生成和实验设置中的相关超参数. MBTA的策略模型和实例数据集生成的详细信息可以参考本文公开的代码 [28] .
表1数据集生成和实验设置中的相关超参数设置
Table1Related hyperparameters setting in datasets generation and experiments setup

4.1 性能评估与分析
定义n ν表示执行任务的智能体数量,n ν max表示编码器可对执行任务的智能体进行编码的最大数量,且. 当时,对智能体进行编码时将相应空缺位置的元素用 0填充. 为了充分验证MBTA的性能,分别在给定,,队列Qh的长度h和待分配的任务节点数量n为不同值的情况下对算法的性能进行评估和分析. 此外,定义MBTA---h-n 和AttenTD---h-n分别表示不同参数设置下参与评估的任务分配方法的名称.
图3展示了MBTA在不同参数设置下的路程代价、紧急程度代价和协同代价在多个批次数据下的平均值的对比评估结果. 图中的横坐标表示训练次数,纵坐标表示代价值,且这些代价值是在每一次训练结束后在多个批次的测试数据集上的评估结果. 为了验证MBTA的有效性和优势,在执行任务的智能体数量和队列Qh的长度h为不同值的条件下验证MBTA的代价收敛情况.
如图3中的子图(a)(d)(g)(j)所示,n ν越大,相应代价的初始值也通常越大. 但随着训练的进行,在测试中除了路程代价,不同n ν下的MBTA对应的代价会最终收敛到近似的值. 由此可以推断,即使执行任务的智能体数量和类型发生变化,MBTA中的递归嵌入结构依然可以配合智能体选择解码器选择出最适合执行任务的智能体,以最小化相应的代价函数. 因此,在该评估中可以验证MBTA或递归嵌入结构是有效的. 此外,如图3(d)所示,在训练的最后阶段路程代价也存在一定的差异,这主要是因为MBTA在任务分配中以放弃一定的路程代价来降低紧急程度代价和协同代价.



图3MBTA在不同参数设置下的路程代价、紧急程度代价和协同代价的对比评估
Fig.3Comparative evaluations of distance cost, urgency cost, and collaboration cost of MBTA under different parameter settings
如图3中的子图(b)(e)(h)(k)所示,h越大,相应的路程代价就越大,但对应的紧急程度代价和协同代价反而越小. 由此可以推断,在一个批次的任务分配中如果可选择的智能体数量增加,MBTA中的递归嵌入结构会配合智能体选择解码器和任务节点选择解码器选择更多的智能体协同执行任务,且也会优先选择更多的智能体去执行更紧急的任务,以最小化相应的代价函数. 此外,由图3(e)可知,随着队列Qh的长度h增大,在批次任务分配中会牺牲一定的路程代价来最小化协同代价和紧急程度代价.
如图3中的子图(c)(f)(i)(l)所示,在任务节点数量 n变化的情况下,随着策略的逐步训练,路程代价、紧急程度代价和协同代价的评估曲线都逐渐减低. 此外,相应的代价随着任务节点数量n的增加也会逐步增大,其符合任务分配的代价函数变化规律. 由此可以推断,在任务节点数量n变化的情况下,MBTA能够稳定且高效地进行批次任务分配.
4.2 对比评估与分析
以上实验对MBTA在不同参数配置下的批次任务分配能力的有效性进行了充分验证,本小节则将MBTA和AttenTD进行对比评估和分析. 考虑到AttenTD 一轮只能选择一个智能体–任务节点对,其任务分配方案并不强调让智能体协同执行任务. 此外,由于 AttenTD没有批次任务分配的功能,在AttenTD的评估中设置n = n ν,且h = 1; 在MBTA的评估中则设置h = 10. 将MBTA和AttenTD在智能体数量n ν变化情况下关于路程代价和紧急程度代价进行对比评估,评估结果如图4所示.

图4MBTA和AttenTD在n ν变化下的路程代价和紧急程度代价对比评估
Fig.4Comparative evaluations of distance cost and urgency cost between MBTA and AttenTD under different values of n ν
如图4中的子图(a)和(b)所示,随着n ν从10增大到 15,MBTA的路程代价在策略训练后期相较于AttenTD的路程代价更低. 由此可以推断出,随着执行任务的智能体数量增多,MBTA的递归嵌入结构能够配合智能体选择解码器和任务节点选择解码器在一个批次的任务分配中从n ν个智能体中选择出较优的智能体来执行任务. 并且,在对抗任务和夺控任务的任务分配中,MBTA相较于AttenTD能够在批次任务分配中指定智能体协同执行任务.
如图4中的子图(c)和(d)所示,无论n ν取何值,MBTA的紧急程度代价都明显低于AttenTD的紧急程度代价. 由于MBTA在一个批次任务分配完成后相应的智能体即可执行分配到的任务,在策略训练初始阶段MBTA的紧急程度代价就明显低于AttenTD的紧急程度代价. 该评估结果表明,MBTA相比于AttenTD能够在批次任务分配中选择更优的智能体来执行更紧急的任务.
5 结论
本文提出了一种多类型任务下的异构多智能体批次任务分配方法MBTA,模拟紧急任务场景下多智能体执行多类型任务的仿真实验表明,MBTA能够在一个批次任务分配中优先选择较优的智能体去执行更紧急的任务,且在批次任务分配中具有使智能体协同执行任务的能力,提高了算法在紧急任务场景下的实时性和可靠性. 未来,将在实际救援场景下的任务分配中对MBTA算法进行应用和验证.