摘要
鉴于生产过程中订单的随机到达可能导致调度方案无法实现最优, 实时动态订单到达成为关键问题. 针对动态多重柔性作业车间调度问题(DMFJSP), 提出了多策略决斗双深度Q网络(MPD3QN)求解方法. 该问题考虑了工件订单和多类型工件的动态到达, 首先, 为了降低DMFJSP的复杂性, 提出了一个简化的流体松弛模型, 并基于流体模型设计了多指标选择策略, 用于辅助生产调度决策. 其次, 进一步构建了马尔可夫决策过程(MDP)模型, 提取了与工件和机器相关的19个状态特征, 设计了20种复合规则作为动作空间. 然后, 结合优先经验回放、软更新机制和自适应动作选择策略, 提出了MPD3QN算法. 最后, 通过81个测试算例, 将所提算法与3种现有的深度强化学习调度方法进行比较, 仿真结果验证了其优越性.
关键词
Abstract
Due to the random arrival of orders during production, companies may face challenges that result in the execution of a scheduling plan that is not optimal. The real-time dynamic arrival of orders is a critical issue. To address the dynamic multiplicity flexible job-shop scheduling problem (DMFJSP), which involves dynamic arrivals of job orders and multiple job types, a multi-policy dueling double deep Q-network (MPD3QN) solution is proposed. Firstly, to reduce the complexity of DMFJSP, a simplified fluid relaxation model is introduced and a multi-criteria selection strategy is developed based on this model to aid production scheduling decisions. Secondly, a Markov decision process (MDP) framework is constructed by extracting 19 state features related to jobs and machines, and 20 composite rules are designed to form the action space. Then, the MPD3QN algorithm is formulated through the integration of prioritised experience replay, a soft update mechanism, and an adaptive action selection strategy. Finally, the proposed method is evaluated through 81 test instances, and its performance is compared against three existing deep reinforcement learning scheduling approaches. Simulation results confirm its superior performance in scheduling efficiency and robustness.
1 引言
柔性作业车间调度问题(flexible job-shop scheduling problem,FJSP)是传统作业车间调度问题(jobshop scheduling problem,JSP)的扩展. 与JSP不同,FJSP不仅需要对每个工件的工序进行合理排序,还需要考虑不同机器和资源的分配及其灵活性 [1] . 通过允许工序在多台机器上执行,FJSP可以增强生产系统的适应性和灵活性,打破对单一资源的依赖,使企业能够动态选择最优的资源配置,以优化生产效率.
在柔性作业车间中,制造系统可能需要处理不同类型的工件. 如,类型A的工件需要高精度的铣削和抛光,类型B的工件则涉及切割、焊接和装配. 每种工件类型可能需要特定的机器设置、不同的工序顺序或不同的资源约束. 此外,面对动态环境,如随机订单插入,由于无法提前确定所有工件的到达时间和数量,调度计划常常会被打乱,从而降低其可靠性,并需要调度系统不断调整 [2] . 上述问题可抽象为动态多重柔性作业车间调度问题(dynamic multiplicity flexible jobshop scheduling problem,DMFJSP). “动态约束”一词指的是工件订单的动态到达,而“多重约束”指的是每个订单中包含多种类型的工件,而且每种工件类型对应着不同数量的工件需求. 它突破了传统柔性作业车间调度的局限,充分考虑工件订单动态到达和多类型工件的约束,从而能够帮助企业更合理地分配资源,应对生产过程中的不确定性,推动行业向智能化、高效化方向发展 [3] .
近年来,智能优化算法推动了柔性作业车间调度问题的研究 [4] . 如基于自适应加权和禁忌搜索策略 [5]、量子退火算法 [6]、量子粒子群优化算法 [7]、数据驱动进化算法 [8]、质量–多样性算法 [9] . 然而,尽管智能优化算法在动态环境的研究中取得了一定进展 [10-11],但它们未能充分的虑动态事件的影响,难以有效应对实际生产中的动态挑战. 基于深度强化学习的端到端实时调度是提高调度系统快速响应动态事件的有效解决方案 [12] . Luo [13] 提出了一种基于深度Q网络(deep Q-network,DQN)的调度方法,用于解决新工件插入的动态问题. Chang等人 [14] 通过将双重深度Q网络(double deep Q-network,DDQN)与自适应 ε贪婪策略相结合,提高了学习效率和调度性能. Du等人 [15] 采用决斗双深度Q网络(dueling double deep Qnetwork,D3QN),显著提高了调度稳定性并优化了完工时间.
尽管已有优化方法为解决DMFJSP带来更多可能 [16],然而,大多数现有研究集中在更简单的动态环境或单任务调度场景,其在应对复杂生产环境方面的潜力尚未得到充分探索 [17] . 因此,本文研究旨在通过将简化的流体松弛模型、深度强化学习算法以及创新的调度策略相结合,提高DMFJSP的求解效率和质量.本文主要贡献如下:
1)详细描述了 DMFJSP,并设计了简化的流体松弛模型来降低 DMFJSP的复杂性和实现端到端的 D3QN方法.
2)基于简化的流体松弛模型提出了工序和机器分配的多种选择指标,从而增强了模型在处理复杂系统时的灵活性和效率.
3)本文设计了与问题特征相关的19个状态特征和20个动作,提出了多策略决斗双深度Q网格(multipolicy dueling double deep Q-network,MPD3QN)框架,引入了优先经验回放、软更新机制以及自适应动作选择策略,实现了所提算法在探索与开发能力的有效平衡.
2 问题描述
2.1 多重柔性作业车间调度问题
在DMFJSP中,有ϱ台机器用于处理n种不同类型的工件. 工件类型Ii由ni个工序组成,这些工序必须按照特定的顺序进行(即优先约束). 每个工序Oi,j可以由多台机器处理,但只能在可用且兼容的机器集合中的一台机器上进行处理 [18] . 在机器Mk上处理的工序集合记为σ(Mk),工序Oi,j的加工机器集合记为Mi,j . 工序Oi,j在机器Mk上的加工时间记为pi,j,k. 生产系统中有d个订单需要处理,订单集合表示为 S =(S1,S2,· · ·,Sd). 每个订单 Ss ∈ S在时间As到达,第1个订单在时间0到达,即A1 = 0. 所有订单中包含的工件类型Ii的数量记为Ni .
基本的约束和假设如下: 1)加工前所有机器均处于空闲状态; 2)每台机器都有无限的缓冲区来存储已完成的工件; 3)在任何给定时间,一个工件只能由一台机器加工,且一台机器一次只能加工一个工件; 4)所有任务都应连续加工,不能被抢占或中断.
2.2 简化的流体松弛模型
流体模型由Bertsimas [19] 提出,通过将离散任务视为连续流体流来解决静态作业车间调度问题,但动态适应性和调度精度不足. 另一个现有模型 [20] 虽可在多个时间间隔内跟踪工件完成情况,却因资源分配灵活性差、约束复杂而效率受限. 相比之下,本文简化的流体松弛模型通过引入时间间隔划分和动态资源分配机制,实现了机器工作时间的精细分配和动态调整,不仅显著提升了动态适应性和调度精度,也简化了约束,提高了求解效率.
在所提的流体松弛模型,引入符号 µi,j.k = 1/pi,j,k,它表示机器 Mk处理工序 Oi,j 的速率. 设 xi,j(ω)为在时刻ω时简化的流体松弛模型中未完成的Oi,j任务数量. 由于用连续流体流替代了离散任务,所以xi,j(ω)是一个非负分数,称之为时刻 ω时工序 Oi,j的流体水平. 时刻 ω时实际调度系统中的未加工的Oi,j任务数量表示为 Xi,j (ω). 决策变量 Ti,j,k(ω)表示时刻ω时求解流体松弛模型得到工序Oi,j在机器 Mk上的总加工时间,(ω)为时刻ω 时求解流体松弛模型得到调度的完成时间.
优化目标:
(1)
约束条件:
(2)
(3)
式(1)表示最小化系统中机器的最大工作量,该目标函数通过平衡和优化所有机器的工作量,实现了整体调度完成时间的缩短. 式(2)保证了每个工序的总需求与机器的处理能力相同. 式(3)表示分配给机器Mk 用于加工工序Oi,j的加工时间必须是非负的.
图1展示了简化的流体松弛模型的流程图. 若在时刻ω有新订单到达,则计算 (ω)和Ti,j,k (ω). 反之,在求解出时刻ω的流体模型后,可依据公式(4)求解后续时刻ω′时工序Oi,j的流体水平. 同时在实际制造系统中进行调度时,能够基于时刻ω′各工序的流体水平提取系统特征,以此指导调度决策.
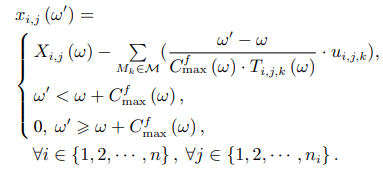
(4)

图1流体松弛模型的流程图
Fig.1Flowchart of the fluid relaxation model
2.3 基于流体松弛模型的工序和机器选择指标
在DMFJSP中有两个关键的决策过程: 工序选择和机器分配 [21] . 工序选择决定在任何给定时刻应优先执行哪个工件,而机器分配则涉及由哪台机器来处理选定的工件. 在实际生产环境中,柔性作业车间调度是一个离散过程,为了生成可执行的调度计划,本文将流体松弛模型的解转化为指导工序选择和机器分配的具体规则. 在此背景下,给出以下3种工序选择指标和两种机器分配指标.
1)3种工序选择指标.
i)资源覆盖度(resource coverage degree,RCD):
ii)流体处理速率(average fluid processing tate,AFPR):
iii)流体优先率(fluid priority rate,FPR):
2)两种机器分配指标.
i)机器闲置率(machine idle rate,MIR):
其中Xi,j,k (ω)和xi,j,k (ω)分别为在时刻ω时,实际制造系统中与流体松弛模型中机器Mk上属于工序Oi,j 的未加工任务数量.
ii)机器负载率(machine load rate,MLR):
3 多策略决斗双深度Q网络
3.1 马尔可夫决策过程
在DMFJSP中,订单的到达和处理是一个动态且复杂的过程,需要在系统状态不断变化的关键时刻做出最优调度决策. 尽管调度状态在持续变化,但对于 DMFJSP而言,决策仅在特定时刻触发: 当没有可处理的工序时,或者当有新订单到达时. 为了有效应对这种复杂性,本文将该问题建模为马尔可夫决策过程(Markov decision process,MDP),能够通过训练智能体以最大化累积奖励来优化调度策略 [22] .
本文提取了19个状态特征,以反映生产系统中关键点的信息以及流程的多指标特性,同时,在状态特征提取中引入了变异系数,变异系数通过消除单位和量纲影响,统一衡量不同特征的离散程度,增强模型对动态变化的敏感性,优化调度决策. 每个状态特征的定义如下:
1)机器总数: ϱ.
2)工件类型总数: n.
3)每种工件类型的平均数:
4)每种工件类型的变异系数:
5)每种工件类型的平均工序数:
6)每种工件类型工序的变异系数:
7)机器的空闲率: Uratio(t)= U (t)/ϱ.
8)机器的平均完成时间:
9)机器完成时间的变异系数:
10)工序的平均完成率:
11)工序完成率的变异系数:
12)平均资源覆盖度:
13)资源覆盖度的变异系数:
14)平均流体处理速率:
15)流体处理速率的变异系数:
16)平均流体优先率:
17)流体优先率的变异系数:
18)平均机器负载率:
19)机器负载率的变异系数:
基于第3.2节提出的多指标策略,引入了5种工序选择规则(operation selection rule,OSR)和4种机器分配规则(machine allocation rule,MAR). 这些规则组合,可得到包含20(5×4)条复合调度规则的动作空间. 表1详细定义了工序选择规则和机器分配规则.
表1动作空间及相应定义
Table1Action space and corresponding descriptions

由于本文的优化目标是最小化完工时间,奖励函数设计如下:
(5)
其中, Ct和Ct−1分别表示决策点t和t − 1的最大完工时间. 从公式中可以看出,奖励与完工时间的增加量成反比. 这种机制促使智能体去选择最佳的策略,从而最小化整体生产周期,提高生产效率.
3.2 自适应的动作选择策略
本文采用了一种自适应的动作选择策略来平衡智能体的探索行为. 在训练阶段,智能体根据动态调整的阈值概率ε来选择动作. 在每个决策点,会生成一个随机数ε′,其中ε′∈(0,1). 如果ε′>ε,智能体将选择具有最高Q值的动作; 否则,它将随机选择一个动作. 阈值概率ε从初始值εstart线性下降到最终值εend. 这种策略确保了智能体在训练初期进行更多的探索,以构建丰富的经验池,而在训练后期,它会更多地利用已学到的经验来选择最优动作. 在决策点t,ε的值记为 εt,其计算公式如下:
(6)
其中,decayt决定了每个决策点的衰减速率. 在本研究中,衰减速率是根据训练周期数和上一周期的决策步数动态计算的. 计算公式如下:

(7)
其中: episodes表示训练周期的总数,step表示上一周期的决策点数量.
3.3 多策略决斗双深度Q网络算法框架
DQN算法作为深度强化学习算法的重要分支 [23],虽然能够利用深度网络结构对动作价值进行预测以确定智能体的行为策略,但其存在对动作价值过高估计的问题,这会导致决策偏差,影响调度效果. DDQN算法在一定程度上缓解了这一问题,通过引入在线网络Q和目标网络QT来减少估计偏差 [24],而D3QN 算法在DDQN的基础上,进一步引入了决斗网络 [25] . 决斗网络的引入使得算法能够更有效地分离状态价值和动作优势,可以更准确地评估每个动作的价值.
本文设计的D3QN网络结构由3个隐藏层组成,每个隐藏层的维度均为200. 在所提取的19个状态特征中,有13个动态特征,为了更全面地捕捉系统的动态变化,提高模型对环境变化的敏感度和适应性. 本文在构建状态空间时,不仅考虑了当前观测状态 st 的动态特征,还加入了当前与前一次观测状态之差 st−st−1,因此输入是一个26维的状态向量,输出则是20种可能动作的Q值. 在上述D3QN框架的基础上,本文提出了MPD3QN,算法1(见表2)和图2均展示了应用MPD3QN来求解DMFJSP的框架流程图.
表2算法 1: MPD3QN框架
Table2Algorithm 1: MPD3QN framework

( 转下表)
( 接上表)

4 仿真实验
本文所提出算法及对比算法均使用 Python 3.7在PyCharm环境中实现. 实验环境为一台配备x64架构的个人计算机,该计算机拥有英特尔(Intel)酷睿(Core)i7-10700 处理器,主频为 2.90 GHz,并配备了 8.00 GB内存.
4.1 测试实例和评价指标
本文采用的测试基准实例是依据Luo [13] 提出的方法随机生成的. 通过机器数量、工件类型数量、新订单数量以及订单到达时间指数分布的平均值(Eave)这4个因素进行组合,生成了81(3×3×3×3)个不同的测试实例. 为评估算法性能,除完工时间这一指标外,本文采用相对百分比增长(relative percentage increases,RPI)作为性能度量指标,如式(9)所示:
(9)
其中: Cmax表示某一算法针对某个实例所得到的完工时间,Cbest表示所有参与对比的算法针对该实例所取得的最优完工时间. 此外,本文引入了胜率 [26] 这一重要评估指标,其指的是算法在测试实例中取得最优结果的比例.

图2MPD3QN流程图
Fig.2Flowchart of MPD3QN
4.2 MPD3QN训练细节
训练实例的规模包含15台机器、10种工件类型以及4个订单插入. 相邻两个订单的到达时间遵循均值为100的指数分布. 训练的具体参数设置如表3所示. 在整个训练过程中,记录了每个周期的累积奖励,并将其展示在图3中. 随着训练的推进,可以观察到累积奖励持续稳定增长. 这表明智能体已经有效地学会了如何在不同的生产场景中选择合适的调度策略,从而提高整体调度效率.
4.3 与现有算法的比较
本节将MPD3QN与其他现有算法进行了对比,其中包括 DRLC [14],DRLL [13],DRLU [27] 和 DRLW [28] . 这些均解决的是与 DMFJSP 密切相关的问题. MPD3QN和对比算法采用相同的训练方法进行训练(对比算法的关键训练参数配置依据其原始论文中的建议,如表4所示),并在81个测试算例上进行测试. 它们的平均RPI、平均Cmax和算法的平均运行时间如表5所示,此外,图4展示了每种方法的胜率比例,以及在测试集上的箱线图和正态分布曲线对比.
表3训练参数
Table3The parameters of the training method

从表5中可以看出,在Eave为50,100,200时,MPD3QN算法在81个不同规模的测试实例上实现的平均 Cmax 值分别为 3 676.9,3 683.2,3 532.9,相比 DRLC,DRLL,DRLU 和DRLW均取得了显著的提高. 同时,MPD3QN在60个实例中比其他3种算法的运行时间更短或相等. 这些结果表明,MPD3QN 算法在解决DMFJSP时具有卓越的鲁棒性和优化能力. 同样,如图4(a)所示,MPD3QN在81个测试实例中的75个实例上实现了最低的RPI值,胜率高达92.6%,远远超过对比算法的胜率. MPD3QN的上述优势在图4(b)中进一步得到体现. MPD3QN 在所有测试中始终呈现出显著更低的RPI 值,且分布非常紧凑,这表明在大多数实例中性能更加稳定.

图3MPD3QN训练过程图
Fig.3Training process diagram of MPD3QN
表4DRLC,DRLL,DRLU和DRLW的关键超参数
Table4The key hyperparameters of DRLC, DRLL, DRLU and DRLW


图4所有算法得到的箱线图、正态分布曲线和胜率
Fig.4Box plots, normal distribution curve and winning rate for all obtained algorithms
表5DRLC,DRLL,DRLU,DRLW和MPD3QN的平均RPI,Cmax和运行时间
Table5Average RPI, Cmax and time values for DRLC, DRLL, DRLU, DRLW and MPD3QN

4.4 Friedman和Wilcoxon signed-rank检验
为了进一步评估DRLC,DRLL,DRLU,DRLW和 MPD3QN的性能差异,本文进行了 Friedman 检验和 Wilcoxon signed-rank检验. 首先,假设各算法的性能没有显著差异,并将显著性水平设为 α = 0.05. 如果 p 值小于 α,则拒绝这一假设. 根据表 6,在RPI 指标上,MPD3QN在排名、均值、标准差、最小值和最大值方面均表现最佳,这些结果不仅证明了MPD3QN提供最优解的能力,还表明其具有较低的方差,显示出在处理DMFJSP时的高度可靠性和效率. 为了进一步验证5种算法之间的性能差异,本文对RPI和Cmax指标进行了Wilcoxon signed-rank检验. 结果详细列于表7,所有81个样本数据集的p值均为0,表明在α = 0.05的显著性水平下,5种算法之间存在统计学上的显著差异.
表6RPI的Friedman检验结果(置信水平α = 0.05)
Table6Results of Friedman test (confident level α = 0.05) by RPI

表7RPI的Wilcoxon signed-rank检验结果
Table7Results of Wilcoxon signed-rank test by RPI

5 结论
本文针对DMFJSP构建了数学模型,引入简化流体松弛模型与多指标选择策略,既降低了问题复杂度,又提升了调度精度. 基于此,提出MPD3QN框架,通过优先经验回放、软更新和自适应动作选择,在动态多订单、多工件类型场景中实现高效探索与利用. 实验表明,MPD3QN显著提高了调度效率和资源利用率. 尽管MPD3QN算法在DMFJSP问题上表现良好,但仍存在局限性. 如,所提方法面向的是部分生产场景,未全面考虑带有AGV集成的实际制造环境. 未来工作将融入绿色调度理念与能耗优化,并结合图注意力机制、深度强化学习和智能优化算法,针对DMFJSP的动态多目标特性设计新的调度策略及实现方案.