摘要
针对具有未知扰动的非线性多智能体系统, 本文提出一种基于记忆事件触发机制并具有隐私保护的合作学习控制算法. 首先, 为防止智能体间交互的关键状态与控制信息泄露, 构造时间掩码函数对整个系统进行隐私保护, 提高加密能力同时减轻对系统性能的影响; 其次, 将记忆事件触发机制嵌入反步法控制框架, 借助该机制对历史数据的存储能力实现安全控制目标; 同时, 利用历史数据设置阈值条件, 避免虚假信号影响通讯并保证系统的瞬态性能; 最后, 提出基于误差的合作学习自适应律. 其不需要预先假定邻居权重是有限的, 从而减少了保守性, 通过理论分析和仿真结果验证所构建事件触发控制方案的可行性.
Abstract
For nonlinear multi-agent systems with unknown disturbances, a cooperative learning control algorithm consisted of a memory-based event-triggered mechanism and privacy preservation is proposed. Firstly, to prevent the leakage of the key state and control information in the interaction between intelligent agents, a time masking function is constructed to provide the privacy protection for the entire system, thereby enhancing encryption capabilities while reducing the impact on system performance. Then, the memory-based event-triggered mechanism is applied within a backstepping framework, and the secure control objectives are achieved by leveraging the mechanism’s ability to store historical data. Meanwhile, historical data is used to set threshold conditions, avoiding false signals from affecting communication and ensuring the system’s transient performance. Lastly, the proposed error-based cooperative learning adaptive rate does not require prior assumptions about the finite nature of neighbor weights, thereby reducing conservatism. The event-triggered control scheme is verified through theoretical analysis and simulation results.
1 引言
近年来,随着无线通信和计算机技术的发展,多智能体系统(multi-agent systems,MASs)的协同安全控制方法得到了一些学者的分析和研究 [1-4] . 然而,网络安全威胁的多元化演进使得系统面临多维安全挑战 [5-7] . 一方面,分布式通信架构易受拒绝服务(denial of service attack,DoS)攻击与中间人攻击,导致协同控制失效; 另一方面,智能体间的开放数据交互加剧了隐私泄露风险,如敌方通过截获状态信息反推系统动态特征. 尤其在存在未知外部扰动的复杂场景下,传统安全控制方法往往难以兼顾实时性、鲁棒性与隐私保护的协同需求,亟需探索新型控制范式.
隐私保护问题通常涉及到如何在保证信息传输的有效性和安全性的前提下,避免敏感数据的泄漏. 随着智能体系统的快速发展,数据共享和协作成为系统性能提升的关键,然而,这一过程也带来了巨大的隐私泄露风险 [8-10] . 传统的加密方法往往依赖固定的加密机制,在智能体之间进行信息交换时难以满足实时性和灵活性的要求. 近年来,研究者们在隐私保护领域已取得一定进展 [11-13] . 其中,文献 [11] 通过构建输出掩蔽函数,提出了一种宝贵的隐私保护机制,避免了系统性能受到随机噪声注入的影响. 基于这一理论成果,许多学者对此进行了研究. 在微电网中,文献 [12] 注入了一种用于电压恢复的隐私保护机制,该机制通过在信息交换期间插入时变输出掩蔽函数来避免泄露初始信息. 这些方法虽然一定程度上提升了隐私保护能力,但仍然面临着适应性和灵活性不足的问题. 因此,如何在保证隐私保护的同时,也能灵活地调整加密策略以适应不同的应用场景,成为了当前研究的重要方向.
与此同时,智能体系统面临着外部扰动和内部不确定性的影响,系统的鲁棒性和实时响应能力至关重要. 为了有效应对这些挑战,事件触发机制被广泛应用于多智能体系统中 [14-16] . 传统的事件触发机制多依赖固定的触发条件,这种方式在面对复杂动态环境时,往往难以适应系统状态的不断变化. 为了解决这一问题,记忆事件触发机制应运而生 [17] . 文献 [18] 中,设计了一种考虑可变加权函数的记忆事件触发方法. 为了缩短异步间隔,文献 [19] 中提出了一种基于记忆的事件触发机制,该机制使用了历史采样输出. 从以上文献可以看出,记忆事件触发方法可以利用历史数据来更好地计算阈值. 然而,如何设计合理的记忆事件触发阈值是一个有趣的研究方向.
此外,随着多智能体协作任务复杂化,合作学习作为关键协调机制,已成为提升系统协同能力的核心技术. 其通过智能体间信息共享与协作,实现自适应律传递以优化学习性能,且取得显著成果. 文献 [20] 中,研究了基于径向基函数神经网络的协同学习能力,并证明了所有自适应律都收敛于其共同的最优值. 文献 [21] 中,作者提出了一种分布式协同自适应控制方法,该方法可以解决未知系统参数的精确自适应学习问题. 然而,现有合作学习算法多假设邻居智能体间权重固定且有界,该假设在实际应用中过于保守,制约系统性能提升. 若能打破此限制,基于邻居智能体控制性能动态调整自适应律传递权重,将大幅提高协同学习方法的有效性与适用性.
鉴于以上分析,本文研究一类具有未知非线性的多智能体系统一致性跟踪问题,提出一种融合记忆事件触发机制与隐私保护特性的合作学习控制方案. 首先,优化了事件触发机制的触发条件,响应逻辑以及数据处理流程. 利用历史数据设置阈值条件,避免虚假信号影响通讯并保证系统的瞬态性能; 其次,构造出用户可自定义时间的遮掩函数去对智能体的初始信息加密屏蔽,防止信息泄露; 同时,基于误差的合作学习控制算法摒弃邻居权重有界的保守假设,减少了保守性并提升了系统性能; 最后,通过理论分析和仿真结果证明了控制方案的适用性.
2 预备知识与问题阐述
2.1 代数图论
本文为阐释智能体间信息交互,引入含N个节点的有向图,其中节点集 =(v1,v2,· · ·,vN)的每个元素对应一个智能体. 边集 ⊆ × 用于刻画智能体间的直接信息传递路径,若(i,j)∈ ,则表示智能体j可直接接收智能体i的信息. 邻接矩阵表征加权图的拓扑结构,当 ai,j >0 时,说明智能体i 可接收智能体 j 的信息; 若 ai,j = 0,则表明智能体i无法从智能体j处获取信息. 入度矩阵该矩阵可直观反映每个节点接收信息的总权重. 在此基础上,拉普拉斯矩阵定义为
假设 1 [22] 在图中,引入生成树的概念,其特征是从根节点到所有跟随节点至少存在一条有向路径. 节点0被指定为生成树的根.
假设 2 [22] yr和分别是领导者信号及其导数,二者均是有界的.
引理 1 [22] 定义若存在 bi >0,则矩阵是非奇异的.
引理 2 [23]定义向量则以下不等式成立:
其中表示矩阵的最小奇异值.
2.2 系统描述
第i(i = 1,· · ·,N)个智能体的系统模型为
(1)
其中: 系统的状态向量表示为系统中未识别的动力学是未知的光滑非线性函数; gi,·是有界且未知的外部扰动; ui和yi分别是控制输入信号和控制输出信号.
控制目标: 针对具有未知扰动的非线性多智能体系统,在保障隐私安全的前提下,通过设计融合记忆事件触发机制与合作学习的控制策略,实现跟随者智能体对领导者信号的一致性跟踪,即保证所有跟随者的输出yi最终收敛至领导者信号yr的邻域内,且闭环系统中所有信号均为半全局最终一致有界.
2.3 隐私保护
为了更有效地实现隐私保护的控制目标,受文献 [24] 的启发,提出一种自定义时间掩码函数,该函数能够在用户设定的时间窗口内对数据进行加密处理,从而确保数据在此期间获得保护. 通过动态调整时间屏蔽的持续时长,系统能够根据实际隐私需求灵活控制数据保护的范围,避免过度加密对系统性能的影响. 所提出的自定义时间掩码函数形式如下:
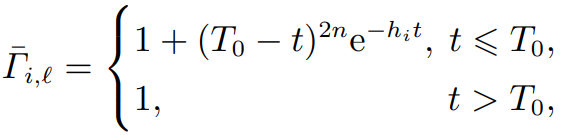
(2)
其中: T0是用户定义的时间参数,表示掩码的持续时间,它是一个正数; hi是一个正常数. 值得指出的是,及其导数在任意时间点均为连续的. 根据这一掩码函数,对系统状态进行变换可以得到
(3)
其中是经过掩码函数变换后的系统状态.
注 1 本文提出的掩码函数(2)能够灵活地设定隐私保护持续的时间. 当t → T0时,系统状态会逐渐趋近于这表明掩码函数能够在有限时间内有效地保护隐私. 一旦达到预定的时间,系统状态会恢复到未加密的状态,从而减少隐私保护对控制精度的影响. 此外,通过调整中的参数hi,可以为不同的通信通道设计不同的掩码函数,进一步增强隐私保护的加密能力,提高系统的安全性.
注 2 隐私保护的持续时间T0过小,加密时间不足,敏感性下降,可能导致初始敏感信息泄露; 若过大,加密状态持续时间过长,敏感性增强,会因掩码函数的时变特性引入额外动态,影响控制精度. 实际选择需结合系统初始阶段的隐私敏感程度.
对式(3)进行求导运算,可以得到
(4)
进一步推导,通过对式(4)进行变形和化简,利用数学关系可以得出
(5)
根据式(3),从数学映射的角度出发,其逆映射可表示为
(6)
基于给定的系统模型(1),能够推导出
(7)
为了简化表达式,令则式(7)可以简化为
(8)
类似地,通过一系列的数学推导和变换,最终得到变换后的系统模型为
(9)
其中:代表经过变换后具有隐私保护的系统状态,而是未知非线性函数.
引理 3 针对原系统(1)和变换后的系统(9),有以下性质: 变量与在实数域上存在一一映射关系. 这意味着对于每一个的取值,在中都有唯一的与之对应,反之亦然. 并且,及其导数在任意时刻均保持连续性.
引理 4 [25] 对于存在描述为的模糊逻辑系统,可以满足以下不等式:
其中: f(x)是紧集Ω下的未知连续函数,表示最优参数变量,表示模糊基函数向量,δ表示近似误差.
引理 5 对于r ≥ 2,二阶滑模积分滤波器表示为

其中: J(t)是滤波器的已知输入信号; 是滤波器的状态; 都是可以设计的正参数.
2.4 扰动观测器设计
首先,根据引理4,可以近似估计未知非线性函数为
(10)
根据系统模型(9),则系统可以再次转化为以下形式:

接着,设计扰动观测器为
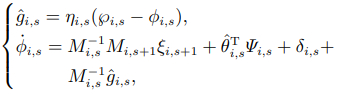
(11)
其中:是一个正常数; 和分别是和的估计值,且各自的估计误差均满足
对进行求导,可得
(12)
则最终计算干扰观测器误差的导数得到
(13)
2.5 记忆事件触发机制
相较于普通的事件触发机制,记忆事件触发机制是一种通过历史状态数据的积累与动态阈值判断来优化控制更新的策略. 其核心思想是仅在系统状态偏离预期或达到特定条件时触发控制调整,而非固定时间间隔更新,从而减少计算与通信资源消耗.
本节将介绍记忆事件触发机制. 首先,描述自适应控制信号为
(14)
接着,设计记忆事件触发机制为
(15)
其中:表示第i个智能体的同步误差变量,其定义为为第n − 1步设计的虚拟控制变量; 表示控制信号的采样误差; 表示第i个子系统中时间发生的时刻; 和均为正的设计参数; 为时变的阈值参数且满足
记忆事件触发机制可在更新的阈值参数上得以体现,具体的更新规则如下:
(16)
其中表示时变参数的更新时间. 当满足上述触发条件时,依据规则更新得到的新时变参数将会被应用到式(15)中,从而对系统的后续运行产生影响.
Di和Ei的具体描述如下:
(17)
其中:和均是正参数且满足1 和m为释放数据包的数量,它是一个正整数,不难发现,当m = 1时,记忆事件触发机制变为普通的事件触发机制.
3 控制器设计和稳定性分析
3.1 控制器设计
描述同步误差以及坐标变换为
(18)
其中:表示邻接矩阵; 是虚拟控制变量; 为一个类似于的掩码函数.
第1步 根据式(18)求导得出
(19)
选取李雅普诺夫函数为
(20)
对以上的李雅普诺夫函数进行求导,可得
(21)
接着,对其中的未知函数进行近似估计可以获得
(22)
代入式(13)和式(22),可以得到
(23)
利用Young’s不等式以及条件
可以得到
(24)
设计神经网络的权重自适应律为
(25)
其中为正设计参数.
注 3 在本文中,自适应律考虑了基于误差的合作学习 [26] 算法. 所设计的策略整合邻居信息,这一设计使得各智能体能够在学习过程中相互协作. 通过引入额外的误差函数合作学习控制能够在不依赖邻居信息有界这一假设的前提下,直接通过设计控制器来满足半全局最终一致有界条件.是一个动态调整函数,该函数能够根据邻居跟踪误差的大小动态调整智能体j的自适应律权重. 具体而言,当邻居跟踪误差较小时,的值相对较大,从而增加智能体j的自适应律权重,使其在协同学习中发挥更大的作用; 反之,当邻居跟踪误差较大时,的值相对较小,智能体j的自适应律权重将被降低,以减少其对合作学习性能的负面影响.
根据自适应律,可得
(26)
再由不等式
进一步得到
(27)
设计虚拟控制器为
(28)
其中设计参数再根据Young’s不等式,可得

代入虚拟控制器,李雅普诺夫函数的导数化简可得
(29)
其中
第步由前式可知对该式求导则有. 由于虚拟控制器的导数需要大量的计算资源. 因此,为了避免复杂性爆炸的问题,引用二阶滑模积分滤波器,估计虚拟控制器的导数值为
(30)
选取李雅普诺夫函数为
(31)
考虑权重自适应律为
(32)
其中为可设计的参数.
选择虚拟控制器为
(33)
其中是一个正常数. 当s = 2时,虚拟控制器为
(34)
化简可得
(35)
其中
第n步 类似于第s步,将虚拟控制器通过二阶滑模积分滤波器近似为
(36)
基于前式可知
(37)
选择李雅普诺夫函数为
(38)
对上式进行求导,再由Young’s不等式放缩,可以得到
(39)
为了避免不必要的资源浪费,引入记忆事件触发机制,定义自适应控制信号为
(40)
由此可得
(41)
设计自适应律为
(42)
构建实际连续控制信号为
(43)
接着,在采样区间可以从式(15)中得知其中,和均为时变函数,且满足由此可以得到关系式
(44)
将式(44)代入到式(33)中,可得
(45)
根据条件已知则存在又由双曲函数tanh(·)的性质可以得知
(46)
随后,将式(40)和式(42)代入到式(45)中,得到
(47)
其中
定义其中随后,得到
(48)
3.2 稳定性分析
本节采用Lyapunov函数对多智能体系统进行稳定性分析.
定理 1 针对存在未知扰动的非线性多智能体系统(1),设计了隐私保护机制(44)、扰动观测器(11)、记忆事件触发机制(15)、协同学习自适应律(25)(32)(42)以及虚拟控制信号(28)(33)(43),并且在假设1,2 成立的条件下,所设计的控制方案能够确保闭环系统中的所有信号均为半全局最终一致有界的,且能够实现多智能体系统 [27-29] 的一致性目标.
证 定义李雅普诺夫函数为
(49)
对上式进行求导可得
(50)
其中:
依据引理1以及引理2可知,能够得出智能体的跟踪误差是有界的. 同理,其他智能体也具有该性质. 根据文献 [25],通过变换可以得到
(51)
在此基础上,进一步推导可得
(52)
根据引理2,可以保证被限定在一个有限的范围内. 同时,通过理论分析和数学推导也可成功避免芝诺现象,关于避免芝诺现象的具体证明过程,可以参考文献 [30] .
4 数值仿真
在本节中,通过仿真证明在基于隐私保护的多智能体系统在受到外部扰动下控制策略的可行性. 考虑由一个领导者和4个跟随者组成的多智能体系统.
定义系统模型为
(53)
定义领导者信号为
(54)
为4个智能体选择不同的掩码函数如下所示:
智能体1: 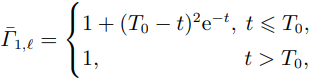
智能体2: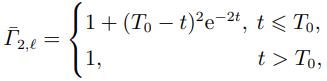
智能体3: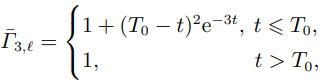
智能体4: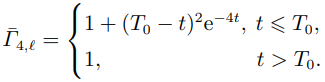
加入隐私保护的领导者信号表示为
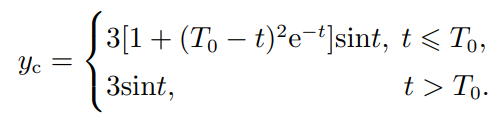
(55)
根据图1可以得知,得到邻接矩阵为
(56)

图1通信拓扑
Fig.1Communication graph
在仿真中,设置4个智能体的初始状态值为x1 =[0 1 0 1]T,x2 = [0 1 0 1]T,x3 = [0 1 0 1]T以及x4 = [0 1 0 1]T. 自适应律的调节参数选择控制器参数为其余设计参数为定义时间参数
首先,图2和图3中,4个智能体跟踪上领导者的轨迹图以及跟踪误差图验证了所设计跟踪控制方案的有效性. 其次,图4分别展示具有隐私保护的两个智能体的状态信号. 不难发现,每一个受隐私保护的智能体都在T0 = 1 s内恢复到原始状态. 然后,图5展示了控制输入信号的轨迹变化. 最后,图6和图7中分别展示了所设计的记忆事件触发机制以及固定阈值策略事件触发机制下的触发效果图,对比可以发现所设计的记忆事件触发机制能更有效的节约通信资源.

图2跟踪轨迹
Fig.2Tracking trajectories

图3跟踪误差
Fig.3Tracking errors
5 结论
本文提出了一种融合记忆事件触发机制与隐私保护特性的合作学习控制方案,旨在提高多智能体系统在未知外部扰动下的鲁棒性和性能,同时确保智能体的隐私安全. 首先,在事件触发机制基础上,优化了触发条件和响应逻辑,通过分析历史数据与系统状态,精确设定触发阈值条件; 其次,提出了一种基于用户可自定义时间的掩码函数,在保证隐私保护的同时实现信息交换. 该加密策略相比传统方法具有更高的灵活性,能够根据不同的隐私需求和应用场景动态调整加密时长,防止信息泄露; 最后,基于误差的合作学习控制算法进一步增强了系统的协作能力,摒弃了传统方法中对邻居权重有界性的保守假设,采用更加灵活的权重更新策略,从而提升了系统性能. 通过李雅普诺夫稳定性理论,证明闭环系统的所有信号是半全局最终一致有界的,并通过仿真实例验证了所提方案的有效性. 在今后的研究中,将聚焦于设计动态调整的机制以延长隐私保护时长,同时在实际系统中验证方法有效性.

图4不同智能体的隐私保护轨迹
Fig.4Privacy preservation trajectories of different agents

图5控制信号
Fig.5Control signals


图6记忆事件触发机制的触发次数
Fig.6The trigger times of memory event-triggered mechanism

图7固定阈值策略事件触发机制的触发次数
Fig.7The trigger times of fixed threshold strategy eventtriggered mechanism