摘要
基于用户交互的进化优化算法可有效提高个性化推荐的性能, 但已有研究忽略了编码个体与解码样本间的偏差, 往往导致算法搜索方向出现较大偏离, 搜索效率低; 此外, 用户交互评价的定量化表示也是较大挑战. 针对此, 本文提出了融合Kalman滤波偏差估计和代理模型的个性化差分进化算法. 首先, 构建了基于用户评价、商品属性等的深度信念网络代理模型, 实现对用户交互的定量评价; 然后, 设计Kalman滤波偏差估计器, 跟踪进化过程中基因型和表现型之间的偏差, 并基于该偏差设计差分进化算子, 改变种群分布并引导搜索方向; 最后, 将该算法应用于亚马逊个性化搜索数据集, 验证了其有效性.
Abstract
User interaction-based evolutionary optimization can effectively improve the performance of personalized recommendation. However, existing studies have overlooked the deviation between the encoded individuals and the decoded candidates, often resulting in a significant deviation in the search direction and low search efficiency. Moreover, the quantitative representation of user interaction evaluation is also a major challenge. To address this, this paper proposes a personalized differential evolution algorithm that integrates Kalman filter deviation estimation and surrogate models. Firstly, a deep belief network trained with user evaluation and product attributes is constructed to achieve quantitative evaluation of user interactions. Then, a Kalman filter estimator is designed to track the deviation between genotypes and phenotypes during the evolution process, and a differential evolution operator is designed based on this deviation to change the population distribution and guide the search direction. Finally, this algorithm is applied to the Amazon personalized search dataset to verify its effectiveness.
1 引言
近年来,智能终端、社交App、电商平台等快速发展,产生了大量用户生成内容(user generated content,UGC),如用户评分、商品类别标签、文本评论、图片、视频或社交关系等. UGC具有多源异构异质特性,综合反映了用户对搜索条目的喜好和兴趣. 显然,它对深入挖掘用户真实兴趣偏好、提供优质个性化搜索服务是有价值的 [1-2] .
个性化搜索的目的是从众多产品中找到最符合用户偏好的一款或多款,且所处理的决策变量往往是高维离散的,本质上是一种复杂离散的优化问题 [3] . 进化算法(evolutionary algorithms,EAs)作为一种随机搜索算法,其无需函数模型的任何梯度信息,也不用考虑函数是否具备连续性,在解决复杂离散优化问题方面的能力尤为突出. 但不同用户的偏好需求会有所差异,他们“满意”的目标不能用明确的数学表达式 [4] 来表示,导致传统的进化优化算法在进行个性化搜索时存在建模困难的问题. 代理辅助进化算法(surrogateassisted EAs,SAEAs)通过使用代理模型代替实际的目标函数,不仅可以有效减少计算成本 [5],还能够准确地对优化目标进行建模 [6],更适用于处理个性化搜索问题. 在使用SAEAs 解决个性化搜索问题时,需要构建精确描述用户兴趣偏好的代理模型. 常见代理模型构建使用的方法包括径向基函数模型 [7-8]、多项式回归模型 [9]、神经网络 [10-11]、克里金模型 [12]、支持向量回归模型 [13] 等. 例如,Bao 等 [14] 提出了一种受限玻尔兹曼机辅助的交互式分布估计算法,提高了交互式分布估计算法在个性化搜索中的应用; Wu等 [15] 提出了一种基于多维偏好用户代理模型的交互式多因子进化优化算法,通过多任务优化在偏好间迁移知识,实现推荐多样性和新颖性的提升. 这些方法的成功应用说明了用户生成内容对构建偏好代理模型的有效性,同时也展示了构建代理模型对进化算法求解个性化搜索问题的必要性.
在使用SAEAs解决个性化搜索问题时,初始种群的个体编码通常是不同形式的商品数据向量化后组合得到. 在执行各种遗传算子后,不可避免地会产生一些新的编码个体,搜索到的最优解个体往往解码后与真实的商品个体无法对应,存在着一定的偏差. 这种偏差一旦产生就会大概率一直存在,使得进化算法会向着新产生编码个体的最优解方向搜索,从而偏离真实样本的方向. 以往研究往往根据距离选择最优解一定范围内的最优真实个体进行输出,而没有从根本上解决或者缓解这一问题. 进化算法搜索过程如图1所示.

图1进化过程偏差变化示例
Fig.1An illustrative example of deviations in evolutionary processes
图1中,黑点代表进化过程中的个体; 红点代表算法搜索到的当代最优解; 蓝色六角星代表当代最优真实样本解; 绿色六角星代表最优真实样本解; 横轴代表进化的代数. 可以看到,每一代算法最优解与当代最优真实样本解间往往存在一定偏差,这种偏差随进化过程不断变化,且算法搜索方向会受其影响逐渐偏离最优真实样本解,从而导致最终搜索到的最优解并不是真正的最优样本解,严重影响了个性化进化搜索的准确性. 因此,追踪进化过程中存在的上述偏差,并采用必要的措施进行修正,对于智能优化算法求解个性化搜索问题具有重要意义.
卡尔曼滤波 [16](Kalman filtering,KF)是一种对动态系统进行最小偏差估计的方法,可以准确地对偏差状态进行估计. 但它只能应用于线性系统,且要求噪声为高斯白噪声,对于实际生产生活中常见的非线性系统则不再适用. 为此,产生了许多改进的卡尔曼滤波,如扩展卡尔曼滤波(extended KF,EKF)、无迹卡尔曼滤波(unscented KF,UKF)、容积卡尔曼滤波(cubature KF,CKF)和集合卡尔曼滤波(ensemble KF,EnKF)等. 这些改进的卡尔曼滤波方法作为各种复杂动态系统状态估计的主流算法,具有实时、快速、高效、抗干扰能力强等优点,已经得到了广泛的应用. 例如,Yang等 [17] 重点研究了基于间歇测量的目标跟踪状态估计问题,利用后验测量提出一种修正卡尔曼滤波,以提高当前估计状态的精度; Sun等 [18] 关注传感器网络上的分布式状态估计问题,设计了一种分布式卡尔曼滤波算法; Yang等 [19] 研究一种分布式立方卡尔曼滤波算法,用于大规模电力系统的动态状态估计. 此外,卡尔曼滤波在进化优化领域也发挥着重要作用. 例如,Chen等 [20] 将集合卡尔曼滤波引入动态多目标优化问题中,对环境变化后的种群中心点进行预测; Gutiérrez 等 [21] 提出一种基于约束进化计算的机器人自定位模型,通过使用基于卡尔曼滤波的阶段位置估计,以重新定义遗传算法的搜索空间,从而找到机器人最准确的当前位置; Muruganantham等 [22] 为了更好地解决动态多目标优化问题,提出了一种基于卡尔曼滤波预测的决策空间动态多目标进化算法,通过卡尔曼滤波跟踪最优解的变化,引导搜索朝着变化的最优解方向寻找,从而加速收敛. 以上研究表明卡尔曼滤波是进行状态估计的有利手段,且与进化算法的结合是可行的.
基于以上内容,本文考虑充分挖掘不同用户生成内容包含的用户兴趣偏好信息,包括用户文本评价、用户评分和项目类别3类连续、离散混合数据,利用深度信念网络(deep belief network,DBN)强大的特征学习能力构建用户偏好代理模型; 在差分进化算法(differential evolution,DE)的框架下,使用 DBN 偏好代理模型为进化个体提供量化的适应度评估,设计基于DBN 用户偏好代理模型的个性化进化搜索算法; 考虑到进化过程中每一代编码空间搜索到的可能解与解码空间中真实可行偏好离散解间普遍存在一定的偏差,设计了有效的 Kalman 滤波器对其进行估计和跟踪,并根据估计偏差调整种群中个体的编码,使得新种群在编码空间中的分布更靠近解码空间中的真实可行偏好离散解,从而,减小进化过程中编码空间产生的可能最优解与解码空间中真实可行偏好离散解间偏差对搜索过程的影响,引导进化过程向着用户偏好的真实样本解方向前进,帮助更好更快地找到最优真实样本解.
本文贡献主要包括3个方面: 1)针对以往用户兴趣偏好特征提取不全面的问题,利用DBN充分挖掘多种用户生成内容包含的用户兴趣偏好信息,构建偏好代理模型; 2)针对传统进化优化算法无法有效解决离散个性化搜索问题,提出DBN代理模型辅助的差分进化算法; 3)针对 DBN代理模型驱动的差分进化算法在进行面向用户生成内容的个性化搜索时存在偏差的问题,设计了Kalman滤波估计器,对进化过程中的偏差进行估计并根据估计偏差对种群个体进行更新,从而实现代理模型驱动的Kalman偏差估计个性化差分进化搜索算法.
本文后续内容组织如下: 第1节给出所提算法框架; 第2节具体说明DBN驱动的差分进化算法、基于卡尔曼滤波的偏差估计以及融合偏差估计的差分进化种群更新策略; 第3节给出实例分析; 最后总结本文工作.
2 算法框架
本文所提算法框架如图2所示.

图2DBN-Kalman-DE算法框架
Fig.2The framework of DBN-Kalman-DE algorithm
考虑到个性化搜索的物品描述主要由用户文本评论和商品基础信息组成,首先对这两种用户生成内容进行一定的处理与编码转换,得到不同商品的向量化表示. 由于在使用差分进化算法进行个性化搜索时,无法为进化个体建立明确的适应度函数,所以这里使用DBN挖掘不同商品的向量化表示与对应商品综合评分之间的关系,构建DBN偏好代理模型,作为进化算法的适应度评估函数,实现对进化个体的适应值估计. 此外,考虑到进化过程中编码空间的最优解与解码空间的真实可行离散解间存在一定的偏差,进一步设计了Kalman滤波偏差估计器对其进行跟踪与估计,并根据估计得到的偏差更新种群中的个体分布,调整搜索的方向,加速搜索的进程,提高面向多源异构 UGC个性化搜索的差分进化算法综合性能.
算法主要包含3个部分: 1)使用70%处理过的UGC数据对DBN进行训练,得到用户偏好代理模型; 2)将构建好的代理模型作为差分进化算法的适应度函数,实现DBN代理模型辅助的差分进化算法; 3)融入 Kalman滤波偏差估计器,将进化过程中每一代编码空间的个体与解码空间中真实可行偏好离散解间的偏差作为Kalman的状态进行估计,并依据估计得到的偏差对种群中的个体进行更新,从而实现代理模型和 Kalman滤波融合的个性化差分进化算法.
3 代理模型和Kalman滤波融合的个性化差分进化算法
3.1 DBN代理模型辅助的差分进化算法
在使用进化算法解决个性化搜索问题时,进化个体为代表不同物品的高维离散向量,其优劣性不能由用户直接给出且无法建立明确的数学表达式进行评估. 因此,有必要构建能够反映用户评价偏好的代理模型,作为进化个体的适应值函数,辅助进化算法完成个体评价.
多源异构 UGC中包含大量的用户历史行为(如: 用户对商品的文本评价、用户对商品的评分、用户位置信息等)和商品基础信息(如材料、类别等),这些数据不同程度地反映了用户的兴趣偏好,同时揭示了商品与评分之间的关联逻辑. 充分挖掘和利用这些信息,能够建立可靠有效的用户兴趣偏好代理模型,构建更精准的“商品→评分”映射关系. DBN是由Hinton在 2006年提出的一种生成模型 [23],由多个受限玻尔兹曼机(restricted Boltzmann machine,RBM)以及一层全连接层构成,拥有强大的特征学习能力和非线性逼近能力,可以准确地建立样本和标签之间的联合分布. 此外,与其他深度神经网络相比,DBN更轻量化,计算代价更小,更适合处理高维离散变量.
因此,本文利用 DBN构建用户偏好代理模型,挖掘多源异构UGC 中用户评价和商品基础信息两类连续、离散混合数据和商品综合评分之间的关系. 图3–4 分别给出了DBN偏好代理模型的构建流程以及DBN 的网络结构.
首先,对用户评价和商品基本属性信息进行预处理、向量化、维度调整以及特征拼接等操作,得到不同商品的向量描述X. 接着,将不同商品的向量描述X与对应的商品综合评分Y 进行配对,构建训练数据集. 在训练时,随机选择数据集样本总数的70%用于建立个性化进化搜索的用户偏好代理模型,另外30%作为寻优的待推荐数据,具体样本数见第4节中的表1. 训练完成后即可得到DBN 偏好代理模型 M1,其输入为进化过程中的个体向量表示,输出为反映用户对该个体偏好程度的适应度评分. 假设某个体的向量表示为x,则其适应度评分y可以通过下式计算得到:
(1)
其中f代表DBN偏好代理模型M1. 用户偏好代理模型构建完成后,即可辅助进化算法进行适应度评估完成搜索,不再需要更新. 这里考虑到DE 相比于其他进化算法具有原理简单、受控参数少、鲁棒性强等优点,本文选择DE作为后续寻优的方法.

图3DBN偏好代理模型构建流程图
Fig.3The flow chart of DBN preference proxy model construction

图4DBN网络结构图
Fig.4The structure of DBN network
3.2 基于Kalman的最优解偏差估计
个性化进化搜索时,种群初始化以及执行交叉、变异和选择算子时,都不可避免地会使得种群中产生并不真实存在的个体. 显然,这样会使得算法每一代寻找到的最优解并不一定真实存在,且与真实样本有一定的偏差,从而导致最终获得的最优解极有可能不是该问题的真实可行离散解. 以往研究大多忽略这种偏差的存在,直接依据距离选择最优解附近Top-N真实样本进行推荐,缺乏一定的可解释性和可靠性. 因此,有必要对进化过程中一直存在的偏差进行处理,降低偏差对搜索结果的影响.
本文拟通过使用进化过程中每一代种群的所有个体与当代较好的真实样本间的偏差对种群中的个体编码进行修正,从而更新种群的个体分布,使得下一代的搜索空间更加接近可行的真实样本解. 考虑到直接修正或者以一定比例修正,即将种群中的个体编码直接加上偏差或者加上一定比例的偏差来更新个体,会导致种群多样性变差,使得算法陷入局部最优,无法找到真正的最优样本解. 因此,本文设计了基于Kalman的最优解偏差估计对进化过程中每一代个体与当代最优真实样本解间的偏差进行估计,其中最优解实际上指的就是当代的最优真实样本解. 使用该偏差估计器得到的偏差各个维度会不同程度的比之前小,从而保证利用此偏差更新的个体可以向真实最优样本解的区域靠近并保持一定的多样性; 另一方面,考虑到进化过程中每一代个体与最优真实样本间的偏差都是动态变化的,因此,整个搜索过程具有非线性特性 [24],这里选择无需线性化假设的集合卡尔曼滤波(EnKF)作为搜索过程中的偏差状态估计器.
对于一个离散的动态系统,其状态空间模型一般描述如下:
(2)
式中: x(k − 1)和x(k)分别是估计前后的系统状态向量; u(k − 1)是k − 1时刻系统的控制向量; z(k)是系统的观测向量; f(·)和h(·)分别是系统的状态转移函数和观测函数; w(k − 1)和v(k)分别为系统k − 1时刻的噪声向量和k时刻的测量噪声向量,通常假设为式(3)中不相关的高斯噪声.
(3)
式中Q和R分别为系统噪声协方差和测量噪声协方差. XP(t)
本文使用Kalman滤波状态估计器的目的是对进化过程中每一个个体与真实样本解间的偏差进行估计,因此,系统的状态向量为每代种群不同个体 与当前代真实样本最优解XP(t)的偏差,其中: t代表进化的代数, i代表第t代种群的第i个个体. 同时,为了保证估计后的偏差能够在各个维度上递减,控制向量必须对状态向量有一定的修正作用. 为此,这里计算与XP(t)个体适应度值和Y P(t)的偏差绝对值为控制向量. 为了保障状态向量和输入向量的量级一致性,需要对控制向量进行一定处理,系统最终的状态向量和控制向量如下所示:
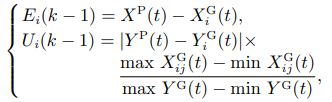
(4)
式中: k − 1 代表估计前的时刻; XP(t)代表t代真实样本最优解,为第t代种群最优解附近一定数量真实样本适应度最高的解,为了同时兼顾效率与精度,经过实验对比后将该数量定为50; Y P(t)为XP(t)对应的适应度值; 是个体 的适应度值; max 和min 分别为第 t 代种群第 i个个体不同维度的最大值和最小值; max Y G(t)和 min Y G(t)则为第t代种群中所有个体适应度值的最大值和最小值.
个性化进化搜索的偏差估计状态方程可以看作是线性的,因此可以转换成以下形式:
(5)
其中: A和B分别是系统的状态转移矩阵和输入矩阵. 假设系统前后时刻的偏差没有直接的关系,这里设定A取单位矩阵I. 而为了将控制向量和状态向量联系起来,使用与前一时刻状态向量Ei(k − 1)相关的符号函数作为系统的输入矩阵,即
(6)
在构建系统观测方程时,将个体的评分值作为系统的观测向量. 考虑到观测向量(评分值)和状态向量(偏差)之间的关系难以用具体的数学表达式表示,进一步训练了径向基函数(radial basis function,RBF)代理模型M2表征该关系,使用和其附近10个真实样本的偏差与对应真实样本评分配对后,构建训练样本集完成对RBF的训练.
故系统的观测方程为
(7)
EnKF的构建包括预测和更新两个步骤,初始时刻随机生成符合正态分布的状态向量集合,对集合中的每一个状态向量进行预测后,再根据预测的结果对系统的状态进行迭代估计与更新. 假定系统状态向量集合的规模为nen,则系统预测与更新的过程如式(8)–(9)所示.
预测:
(8)
更新:
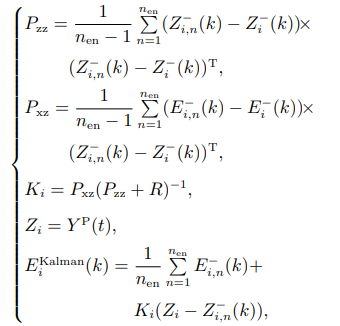
(9)
式中: Ei,n(k − 1)表示k − 1 时刻种群第i个个体偏差随机生成的状态向量集合中第n个状态向量; Ui(k − 1)是相应的控制向量; 表示k 时刻第i 个个体第n 个偏差状态向量的先验预测值; 为 k 时刻状态向量集合预测的均值,也代表第 i个个体最终偏差的先验估计值; 为k 时刻第i 个个体第n 个观测向量的先验估计值; 为k时刻第 i 个个体观测向量集合预测的均值,Pzz为观测误差协方差,反映了观测数据的不确定性; Pxz为状态向量与观测向量的交叉协方差,用于量化状态如何影响观测,通过它就能将观测数据中的信息传递到状态变量的更新中; Ki 为第i 个个体偏差集合卡尔曼增益矩阵,其作用是平衡先验预测与观测数据的权重,实现最优状态估计; Zi 为k时刻系统观测向量的测量值,即第t代种群最优解的适应度值Y P(t); 表示 k 时刻种群第 i个个体偏差的后验估计值,即最终偏差估计的结果.
预测步骤的作用是将 k − 1时刻的状态信息“推移”到下一时刻,生成对 k时刻偏差状态的初步预测. 更新步骤的作用是结合新的观测数据,对预测得到的先验偏差结果进行修正,生成更准确的估计偏差. 这两个步骤从初始时刻开始递归执行,二者协同就可以对每一时刻种群个体与真实样本之间的偏差进行估计,从而为后续偏差的处理提供可靠依据.
3.3 代理模型和Kalman滤波融合的个性化进化搜索
基于第2.1节训练的DBN 代理模型 M1与第2.2节提出的集合卡尔曼滤波偏差估计器,构建代理模型和Kalman 滤波融合的个性化差分进化搜索算法,简记为 DBN-DE-Kalman*,将DBN代理模型作为个性化差分进化算法的适应度评估函数,实现对新生个体的评价,并使用 Kalman滤波偏差估计器对进化过程中编码空间的个体与真实样本解间的偏差进行估计. 记第t 代第i 个个体的偏差估计为(t),利用该偏差引导新个体的生成,方法如式(10)所示:
(10)
最后,选择新种群中适应度值最高的K个个体替代原种群中适应度值最低的K个个体,从而实现集合卡尔曼滤波偏差估计与进化算法的融合. 通过这种方式,就可以降低偏差对进化搜索的影响,引导搜索区域更靠近真实最优样本解,从而加速算法寻找到真实最优样本解的过程. 代理模型和Kalman滤波偏差估计融合的个性化差分进化搜索算法具体流程如图5所示.

图5代理模型和Kalman滤波偏差估计融合的个性化差分进化算法流程图
Fig.5Flow chart of personalized differential evolution algorithm combining surrogate model and Kalman filter deviation estimation
4 实例分析
为了验证所提算法的综合性能,将其应用于亚马逊Toy,Software,Office和Pet 4类商品的个性化搜索数据集中. 这些数据集涵盖了不同类型的用户生成内容,如: 用户 ID、商品 ID、商品基本属性(类别、品牌等)、用户文本评论、用户评论时间、大小为1–5 之间的商品综合评分等. 将用户文本评论与商品基本属性进行向量化表示作为样本的特征描述,商品综合评分则作为样本的适应值,各数据集的样本统计信息如表1所示.
表1数据集统计信息
Table1Data set statistics

实验环境是AMD Ryzen 5 2600 Six-Core Processor 3.40 GHz和16 GB RAM,使用 Python 3.7开发,算法主要参数设置如表2所示. 实验时,各个数据集样本总数的 70%用于DBN代理模型的构建,30%样本则作为待寻优的数据. 采用均方误差(mean squared error,MSE)、平均绝对误差(mean absolute error,MAE)和平均绝对百分比误差(mean absolute percentage error,MAPE)评价代理模型的训练性能,结果如表3所示.
表2实验参数设置
Table2Experimental parameter setting

表3DBN模型精度
Table3The accuracy of DBN model

可以发现,DBN 代理模型在 Office数据集上的 3 个评价指标值均高于其他3个数据集,说明此时模型的精度相对而言是最低的,其原因可能是 Office数据集样本不足,训练不充分导致的.
4.1 Kalman偏差估计器可靠性分析
本文引入卡尔曼滤波偏差估计器的作用主要是对智能优化算法寻优过程中存在的高维偏差进行估计,再基于估计的偏差更新种群中的个体分布,使得更新后的个体能够向更靠近当代最优真实样本解. 为此,估计偏差值应尽可能比实际偏差小. 本文一共设计了包括第2.2节所提卡尔曼滤波估计器Kalman∗在内的4 种卡尔曼滤波器,整体框架都是集合卡尔曼滤波,唯一的区别在于其状态向量和控制向量不同,因此偏差估计的效果有所不同. 下面是另外3种卡尔曼滤波偏差估计器的状态向量和控制向量:
(11)
(12)
(13)
其中,式(13)的min Eij (t)代表 t代种群中第 i 个个体与t 代真实最优样本解XP(t)之间不同维度上偏差的最小值.
为了验证本文设计的 Kalman滤波偏差估计器的效果以及选择最合适的状态向量和控制向量作为估计器参数,对Toy数据集寻优的过程中使用不同的Kalman滤波偏差估计器对偏差进行估计,图6是4种Kalman滤波偏差估计器对搜索过程某一偏差估计前后各维度的数据的分布情况.
图6中蓝色曲线代表估计前偏差在不同维度的值,红色曲线代表估计后的偏差值. 可以看出,图6(a)估计前后没有明显变化,说明Kalman1偏差估计没有明显效果,如果使用这种类型的估计偏差更新个体会使得新个体全部集中在当代样本最优解附近,导致种群的多样性变低,算法容易陷入局部最优; 图6(b)估计后的偏差各维度上大部分都大于真实偏差,如果使用这种偏差进行种群个体的更新,反而会使得种群个体偏离真实样本解; 图6(c)各维度估计得到的偏差都小于真实偏差,但大部分都在0上下,这样会使得对偏差进行修正后新的个体与修正前没有太大区别,对消除偏差的作用不大; 图6(d)红色曲线基本都包含在蓝色曲线中,且与蓝色曲线之间有一定的差距,说明估计得到的偏差明显小于真实偏差,符合预期目标. 因此,这里选择Kalman∗用于后续实验的偏差估计.

图6不同Kalman 偏差估计器估计前后偏差对比
Fig.6Comparison of bias before and after estimation by different Kalman deviation estimators
为了进一步证明 Kalman∗ 滤波偏差估计器的可靠性,在其他3个数据集上进行类似的实验,结果如图7所示.

图7Kalman∗估计前后偏差对比
Fig.7Comparison of Kalman∗ before and after estimation deviations
可以发现,Kalman∗在剩余的3个数据集上估计得到的偏差绝对值也都基本低于真实偏差. 一方面说明本文设计的 Kalman* 滤波偏差估计器能够很好的满足要求,另一方面也证明了 Kalman∗滤波偏差估计器的稳定性与适用性.
此外,为了选择合适的真实最优样本 XP(t),以 Toy数据集为例,用最优解评分值(optimal solution score,OSS)、最优解最近邻真实样本评分值(nearest neighbor score,NNS)、最优解近邻最优样本评分值(best score among neighbors,BSAN)、所需最少进化代数(minimum required evolution times,MRET)4个评价指标测试了不同范围内选择最优真实样本对算法结果的影响,结果如表4所示.
从表4可以看出,在Toy数据集中,随着范围的增加,算法寻找到的真实最优样本解评分会稳定为 5分,且所需最少进化代数也逐渐减少,说明增大选择的范围可以帮助算法更快更准确地找到真实样本最优解. 但考虑到MRET指标反映了算法的计算代价,综合比较,P为50时算法整体性能最好. 因此,后续实验将选择当代最优解附近50个真实样本解中最好的样本作为XP(t)计算偏差.
表4不同范围确定XP(t)寻优结果对比
Table4Comparison of optimization results for determining XP (t) in different ranges

4.2 Kalman*偏差估计有效性验证
为了说明本文所提Kalman*偏差估计器对个性化进化搜索算法的有效性,在4个数据集上对DBN 代理辅助的差分进化算法(DBN-DE)添加/不添加Kalman* 偏差估计器结果进行比较,每组实验独立运行10次取平均值,实验结果如表5所示,最优结果用粗体标注.
表5不同数据集上寻优结果对比
Table5Comparison of optimization results on different data sets

使用致信水平为 0.95的Mann-Whitney U非参数检验对两种算法10次结果进行显著性检验,标记‘*’代表两个算法之间有显著性不同.
由表5可以得到如下结论:
1)本文所提出的DBN-DE-Kalman*算法在除Office之外的3个数据集上性能指标都具有明显优势,总占优率达到83.3%. 不仅最优解最近邻真实样本评分值(NNS)和所需最少进化代数(MRET)明显提升,而且最优解评分值(OSS)和最优解近邻最优样本评分值(BSAN)也较DBN-DE算法有所改善,说明在个性化进化搜索中加入卡尔曼偏差估计可以有效引导搜索方向,快速定位真实最优解.
2)对比DBN-DE-Kalman* 与DBN-DE算法在4个数据集上的MRET指标,可以发现,加入Kalman*滤波偏差估计器后找到最优真实样本解所需最少进化代数明显减少,尤其是在Pet数据集上,加入Kalman*后所需最少进化代数MRET比不加时减少了86%. 说明引入Kalman*滤波偏差估计器后可以有效引导进化算法的搜索方向,减少算法找到最优真实样本解的时间,提高个性化搜索的效率.
3)对比 Office数据集上 DBN-DE-Kalman*与DBN-DE 的表现,发现DBN-DE-Kalman* 算法的OSS和 BSAN指标二者数据差异较小. 如OSS指标,本文所提算法与未含 Kalman误差估计的算法相比较,约下降 0.039,下降率为 0.8%; 对于 BSAN指标,二者相差 0.054,下降率为1.1%. 而NNS指标,所提算法提高约 8.3%; MRET指标提高约62%. 显然,所提算法整体性能仍然有明显优势. 结合4个数据集的样本信息以及 DBN偏好代理模型的精度表现,其原因可能是因为 Office数据集上DBN代理模型精度较低,影响了需要利用适应值信息的卡尔曼偏差估计,进而导致算法搜索方向出现偏离,降低了算法的寻优精度.
为了进一步展示本文所提Kalman* 偏差估计对个性化进化搜索的有效性,接下来以Toy数据集为例,对 DBN-DE-Kalman* 算法和DBN-DE 算法搜索过程中真实样本最优解的变化情况,及搜索结束后最优解附近50个真实样本的评分进行对比,结果如图8–9所示.

图8进化过程真实样本最优解评分变化图
Fig.8Evolution process real sample optimal solution score change chart
从图8可以看出,DBN-DE-Kalman*算法寻找到的真实最优样本解评分值高于 DBN-DE算法,且所需最少进化代数大大减小. 同时,由图9可以看出,搜索结束后DBN-DE-Kalman* 算法最优解附近50 个真实样本的评分均值也比DBN-DE 高. 并且,DBN-DEKalman* 算法最优解附近 50个真实样本评分的方差为0.193 365,而DBN-DE 算法的方差为0.230 134,进一步说明了在个性化进化搜索算法中引入卡尔曼滤波偏差估计器,不仅能显著提高算法搜索到最优真实样本解的效率,而且算法更加稳定.
4.3 与其他个性化进化搜索算法的比较
为了更客观地说明本文所提算法的有效性,将其与6种SAEAs: SVR辅助的差分进化算法(SVR-DE)、 MLP 辅助的差分进化算法(MLP-DE)、融合 SVR与 Kalman*的差分进化算法(SVR-DE-Kalman*)、融合 MLP 与Kalman*的差分进化算法(MLP-DE-Kalman*)、融合 DBN与Kalman1的差分进化算法(DBNDE-Kalman1)和融合DBN与Kalman3的差分进化算法(DBN-DE-Kalman3)对比. 每种算法独立运行10次,记录各评价指标平均值. 实验结果如表6所示,其中最优解用粗体表示.

图9最优解近邻 50 真实样本评分值对比图
Fig.9Comparison chart of the best solution nearest neighbor 50 real sample score values
表6对比实验结果
Table6Comparison of optimization results on different data sets

由表6可以得出以下结论:
1)综合对比不同算法在各数据集上的表现,可以发现: 本文所提 DBN-DE-Kalman∗取得了最优效果. 比如,在Toy数据集中,DBN-DE-Kalman∗算法 BSAN 值为5,说明其找到了最优的真实样本,且NNS和MRET值分别为 4.631和8,也高于次优算法MLP-DEKalman∗ 2.86%和38.46%. 此外,在Pet数据集上,DBN-DE-Kalman∗算法也有类似的表现. 说明在同样的数据集上,深度学习模型DBN具有更强的特征提取能力,可以更加有效的辅助卡尔曼滤波器进行偏差估计;
2)通过对比 SVR-DE 与 SVR-DE-Kalman∗ 以及 MLP-DE与MLP-DE-Kalman∗,可以发现加入Kalman∗偏差估计器的个性化进化搜索算法在 BSAN和 MRET两个指标上均取得了更好的效果,说明本文所提的卡尔曼滤波偏差估计器具有较强的鲁棒性,对于不同代理模型驱动的进化算法,融合卡尔曼滤波偏差估计器均能有效提升搜索的精度和速度;
3)在 Software 数据集上,DBN-DE-Kalman 1 的 MR-ET值取得了最小值1,但是其 BSAN值仅为3.83,说明其在搜索过程中陷入了局部最优,而DBN-DEKalman 3 和DBN-DE-Kalman∗两种算法未出现上述情况,其原因可能是使用Kalman 1 估计器对第1代种群个体进行偏差估计与修正后,种群中个体全部分布于当代真实样本解附近. 因此,设计合适的卡尔曼偏差估计器是确保进化搜索算法有效的根本;
4)通过对比 DBN-DE-Kalman1,DBN-DE-Kalman 3 和DBN-DE-Kalman∗ 3种算法在各数据集上的表现,可以发现DBN-DE-Kalman∗算法虽然在部分数据集少量评价指标没有取得最优值,但综合比较仍获得了最优性能,进一步说明了Kalman∗偏差估计器对于进化搜索算法的有效性. 同时,DBN-DE-Kalman 1和 DBN-DE-Kalman 3各项评价指标对比第3.2节DBNDE 算法均有所改善,说明即使引入的是估计效果不够好的卡尔曼滤波偏差估计器,也可以不同程度上引导进化搜索的方向,提高搜索的准确度.
5 结论
针对面向用户生成内容的个性化进化搜索算法在寻优过程中一直存在的偏差问题,本文提出了一种代理模型和Kalman偏差估计增强的个性化差分进化搜索算法. 首先,利用 DBN提取多源异构 UGC数据中的用户兴趣偏好特征,构建用户偏好代理模型,作为 DE进化个体评价的适应度函数; 然后,构造Kalman 滤波偏差估计器对进化过程中编码个体与真实样本解的偏差进行估计并修正,引导搜索向真实样本最优解的方向靠近,以有效提高个性化搜索的精度与效率; 最后,在4类真实商品数据集上验证了所提算法的有效性和合理性. 根据搜索对象在不同维度的特征,设计面向不同偏好粒度的Kalman偏差估计器,以更有效地引导搜索,将是下一步的研究方向.