摘要
密度峰值聚类算法能够快速高效处理数据集且无需迭代. 但该算法在处理流形数据时, 易错选类簇中心和错误分配样本. 因此, 本文提出面向流形数据的共享近邻和二阶K近邻密度峰值聚类(DPC–SKNN)算法. 首先, 该算法引入逆近邻和共享近邻重新定义局部密度, 充分考虑样本的局部信息和全局信息, 使算法易找到正确的流形类簇中心; 其次, 将样本的关联关系分为K近邻点、二阶K近邻点和非近邻点3种情况, 设计K近邻的分配策略, 增强同一类簇样本的相似性, 提高样本分配的准确率. 将本文算法与8种算法在流形和UCI数据集进行对比, 实验结果表明, DPC-SKNN算法在上述数据集上均获得了不错的聚类结果.
Abstract
The density peaks clustering algorithm can deal with datasets quickly and efficiently without iteration. However, it can sometimes wrongly select cluster centers and misallocate samples when processing manifold data. Therefore, this paper proposes the density peaks clustering algorithm based on shared nearest neighbor and second-order K nearest neighbor for manifold data (DPC-SKNN) algorithm. Firstly, the algorithm introduces reverse nearest neighbors and shares nearest neighbors to redefine local density, fully considering both local and global information of samples, making the algorithm easier to identify correct cluster centers. Secondly, the association relationship of the samples is divided into three types: K nearest neighbors, second-order K nearest neighbors, and non-nearest neighbors, and design allocation strategies for K-nearest neighbors to enhance similarity among samples within the same cluster, thereby improving sample allocation accuracy. DPC-SKNN is compared with eight algorithms on manifold and UCI datasets, and the experimental results show that the DPC-SKNN algorithm obtains good clustering results on all the above datasets.
1 引言
聚类作为一类无监督学习算法,在没有先验知识的情况下,按照某种方式对数据集进行划分 [1],实现同类数据间的相似性最高,不同类数据间的相似性较低. 根据聚类算法的特点可分为多种类型: 基于划分 [2]、基于层次 [3]、基于网格 [4]、基于密度 [5] 和基于模型 [6],它们已广泛应用于文本挖掘 [7]、图像处理 [8]、异常值检测 [9] 等多个领域.
2014年Rodriguez和Laio [10] 在Science提出密度峰值聚类(density peaks clustering,DPC)算法,该算法思想简单高效 [11],且不需要进行迭代. 先计算样本的局部密度和相对距离,随后计算两者的乘积找到数据集的类簇中心,并将剩余样本快速地分配给离其较近的高密度样本所在的类簇. 然而,DPC算法存在一些缺陷: 1)样本的局部密度没有统一的计算度量方法,且其局部密度的定义方式未综合考虑样本的分布特征,易出现错选类簇中心的情况; 2)分配策略仅考虑密度和距离因素,易错误分配样本且出现连锁反应.
为克服DPC算法的缺陷,近年来,学者们做了大量的研究工作,并提出多种改进算法. 针对DPC局部密度定义存在的问题,Zhao等 [12] 结合近邻模糊核函数提出面向密度分布不均数据的模糊与加权共享近邻密度峰值聚类算法(density peaks clustering algorithm based on fuzzy and weighted shared neighbor for uneven density datasets,DPC-FWSN),该算法在计算样本局部密度时考虑了样本的邻域信息,能够平衡各类簇样本密度的贡献,有助于算法选取正确的类簇中心. Zhou等 [13] 提出一种基于核心点识别和KNN核密度估计的鲁棒聚类算法(a robust clustering algorithm based on the identification of core points and KNN kernel density estimation,ICKDC)算法,利用 KNN思想提出一个新的密度估计方法,更容易表征类簇样本的分布差异. Li等 [14] 提出一种基于模糊语义单元的密度峰值聚类算法(an approach of fuzzy semantic cells to density peaks clustering,DPC-FSC)算法,该算法将数据集的样本作为模糊点的模糊语义细胞模型,通过设计合理的粒度原则计算样本的局部密度,将其转化为优化问题. Zhang等 [15] 提出基于平衡密度和连通性的密度峰值聚类算法(density peaks clustering based on balance density and connectivity,BC-DPC)算法,该算法提出的平衡密度设置参数K获取更多的邻域信息,能有效选择正确的类簇中心.
针对DPC算法分配策略的问题,Ren等 [16] 提出基于局部公平密度和模糊K近邻成员分配策略的密度峰聚类算法(density peaks clustering based on local fair density and fuzzy k-nearest neighbors membership allocation strategy,LF-DPC),该算法在分配剩余样本时借鉴广度优先搜索思想,对类簇中心的K近邻点进行快速分配. Xu等 [17] 通过结合图论的思想,提出一种用于自动质心选择和有效聚合的图自适应密度峰聚类算法,使相同类簇的样本具有更高的连通性,从而达到样本准确分配的效果. Zhang等 [18] 结合密度衰减图概念提出基于密度衰减图的密度峰值聚类算法(density decay graph–based density peak clustering,DGDPC),不需要人工选择类簇中心,另外该算法通过设置参数m控制簇合并,有效降低了样本被错误分配的概率. Du等 [19] 提出基于测地距离的密度峰值聚类算法(density peaks clustering using geodesic distances,DPC-GD),在计算样本相对距离时使用测地距离代替欧氏距离,使同一类簇样本间的距离缩短,提高算法分配样本的准确率,但该算法的复杂度较高. 赵嘉等 [20] 提出基于相互邻近度的密度峰值聚类算法,通过计算样本间的相互邻近度衡量样本间的隶属关系,更能体现类簇样本的密集程度,从而更准确地分配样本.
流形数据包含弧线形或环形类簇,在生活中广泛存在,例如: 语音识别 [21]、图像处理 [22] 等. DPC算法处理流形数据时表现出以下不足: 1)两种局部密度定义方式未能同时考虑样本的局部和全局信息,易导致算法在某个流形类簇选取多个类簇中心; 2)在样本分配过程中,由于流形数据集大多数样本远离类簇中心,而DPC算法将样本分配给密度大且距离其最近的样本所在的类簇,易导致样本被错误分配给其他类簇.
为克服DPC算法的上述缺陷,本文提出一种面向流形数据的共享近邻和二阶K近邻密度峰值聚类算法(density peaks clustering algorithm based on shared nearest neighbor and second-order K nearest neighbor for manifold data,DPC-SKNN),DPC-SKNN算法创新点如下: 1)提出一种共享近邻的局部密度,权衡样本共享近邻和非共享近邻样本的相互影响,凸显每个簇的类簇中心,使算法更容易找到正确的类簇中心; 2)设计K近邻的分配策略,将样本间的关联关系分为 K近邻、二阶K近邻和非近邻点,通过这种方式能更好地识别类簇结构,提高同一类簇样本的相似度,从而准确地分配流形数据集样本.
2 DPC算法
DPC是一种典型的基于密度的聚类算法,能够处理非球形类簇并广泛应用于各个领域. DPC算法的主要思想是基于以下两个假设: 1)类簇中心被密度较低的样本所包围; 2)不同的类簇中心相距较远. 对于给定数据集样本xi的局部密度ρi计算公式如下:
(1)
(2)
其中: dij为样本xi与xj之间的欧氏距离,dc为截断距离,DPC原文建议所有样本间的欧氏距离按照升序排列,取值范围在该序列的前1%∼2%之间. 在χ(x)中,若则χ(x)= 0,否则χ(x)= 1. 式(1)–(2)分别为DPC计算样本局部密度的截断核、高斯核计算公式.
样本xi的相对距离δi可以由式(3)求出,即
(3)
在计算局部密度ρi和相对距离δi后分别将其作为 X轴和Y 轴绘制决策图,然后在图的右上方选取类簇中心,为能更准确的选取具有较大局部密度和相对距离的样本,可根据式(4)计算出决策值γi ,选取决策值较大的样本作为类簇中心.
(4)
选出类簇中心后,将剩余样本分配给邻域内密度较高且距离最近样本所属的类簇.
3 DPC–SKNN算法
DPC-SKNN算法主要从两个方面提升DPC算法的聚类效果. 一方面,提出一种新的基于共享近邻的局部密度,它综合考虑了数据集样本的局部信息和全局信息,增大类簇中心和非类簇中心样本间的密度差异,有助于准确识别类簇中心; 另一方面,设计一种K近邻的分配策略,将样本的关联关系分为3种情况,进一步增强同一类簇样本的相似性,使样本分配更准确.
3.1 共享近邻的局部密度
定义 1 样本间的隶属度U(xi,xj ). 通过考虑样本的共享近邻及其周围样本的影响,得到样本间的隶属度函数,如式(5)所示:
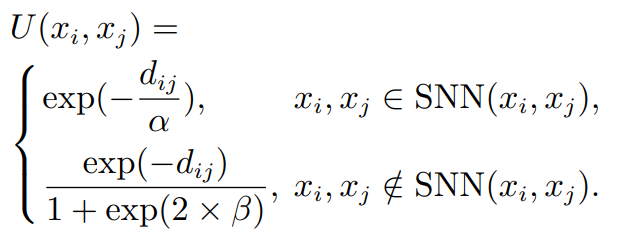
(5)
(6)
其中: dij 表示样本 xi 与样本 xj 之间的欧氏距离,SNN(xi ,xj )为样本xi与样本xj的共享近邻集合,α为调节因子,β为数据集所有样本间欧式距离的平均值,dik为样本xi与其第K近样本间的欧氏距离,N为数据集样本总数.
由上式可知,计算样本间的隶属度分为共享近邻和非共享近邻区域,当样本xi与xj拥有共享近邻区域时, U(xi ,xj )除了与两样本间的距离有关,还受到调节因子α的影响,通过调节因子α增强共享近邻区域对样本局部密度的贡献. 当样本xi与xj不存在共享近邻区域时,U(xi,xj )受到β的影响,考虑了数据集样本的全局信息.
定义 2 共享近邻的局部密度. 对于样本xi的局部密度ρi定义为
(7)
其中: K为近邻数,SNN(xi,xj)为样本xi的共享近邻集合,RNN(xi,xj)为样本xi的逆近邻集合,|set(x)| 为集合set(x)的个数.
计算样本xi的局部密度分为3部分: 第1部分为样本xi周围能与其形成共享近邻区域的样本xj ,权重系数考虑样本的共享近邻个数,进一步增强共享近邻对样本密度的影响,突出自身以及与其有密切关联局部样本的影响力,距离样本越近,贡献越大; 第2部分是样本xi的非共享近邻对样本密度的影响,考虑了样本的全局信息; 第3部分为计算样本的逆近邻个数,能够反映样本的分布情况.
本文定义的局部密度优势在于,不仅考虑了样本间的距离关系,而且考虑是否存在共享近邻区域对样本密度的影响,该过程能够充分利用样本局部信息和全局信息. 同时通过考虑样本的逆近邻个数,算法具有更好的灵活性,在处理不同类型的数据集时,可以通过调整参数K,更好地适应数据集的结构,从而使算法在选择类簇中心时更准确. DPC-SKNN算法的流程图如图1所示.
3.2 K近邻的分配策略
定义 3 二阶K近邻(second-order K nearest neighbors). 样本xi的二阶K近邻KNN2 (xi)表示如下:
(8)
二阶 K 近邻通过考虑样本间的交互与传播过程 [23],将样本的影响力在其二阶邻居中进行扩散. 相比于传统K近邻,二阶K近邻能够更全面地捕捉样本信息,从而更准确地衡量样本的重要性和中心性.

图1DPC–SKNN算法流程图
Fig.1Flowchart of DPC–SKNN algorithm
定义 4 样本xi与xj关联度w(xi ,xj)表示如下:
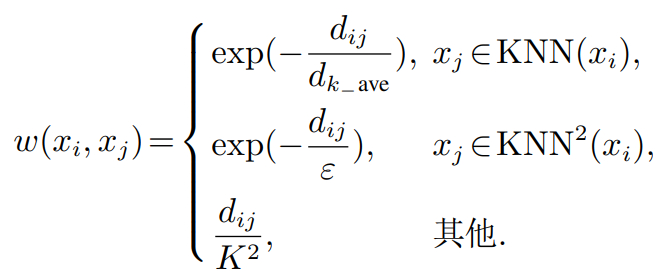
(9)
(10)
(11)
其中: dk−ave为数据集中所有样本与其K近邻的欧氏距离的平均值,dk−ave的计算公式如式(10)所示. ε为数据集中所有样本的K近邻和二阶K近邻去除重复样本的平均距离,ε的计算公式如式(11)所示.
w(xi ,xj)为样本与的关联度,将样本间的关联关系分为3种情况: 1)样本xj为xi的K近邻,此时样本间的关联度最高; 2)样本xj为xi的二阶K近邻(不属于 K近邻),关联度次之; 3)样本xj不属于xi的K近邻和二阶K近邻集合,关联度较小.
定义 5 样本xi与xj的关联度Sim(xi,xj )表示如下:
(12)
其中,计算样本xi与xj之间的相似性时,不仅考虑了样本间的关联度,而且考虑了两样本间是否存在共享近邻区域,若样本间存在共享近邻个数越多,则两样本的相似性越高,表示这两个样本属于同一类簇的可能性越高.
4 实验结果与分析
4.1 实验数据与设置
本节设计了对比实验来验证DPC-SKNN算法的有效性. 分别将 DPC-SKNN算法与 8种对比算法在人工、真实数据集上进行实验与分析. 表1和表2分别给出8个流形数据集和8个UCI数据集的相关属性. 所使用的数据集可在下列网站下载.1
表1流形数据集的属性
Table1Properties of manifold datasets

表2UCI数据集的属性
Table2Properties of UCI datasets

本文选取的对比算法包括: DPC [10],基于模糊加权K近邻的密度峰值鲁棒聚类算法(robust clustering by detecting density peaks and assigning points based on fuzzy weighted K-nearest neighbors,FKNNDPC)[24],基于模糊近邻的鲁棒密度峰值聚类算法(a robust density peaks clustering algorithm using fuzzy neighborhood,FNDPC)[25],基于共享近邻的密度峰值快速搜索聚类算法(shared nearest neighbor based clustering by fast search and find of density peaks,SNN-DPC)[26],基于萤火虫算法优化的密度峰值聚类算法(improved density peaks clustering based on fireflyalgorithm,IDPC-FA)[27],基于连通性估计的密度峰值聚类算法(density peak clustering with connectivity estimation,DPC-CE)[28],基于代表点与K近邻的密度峰值聚类算法(density peaks clustering based on representative points and K-nearest neighbors,RKNNDPC)[29] 和DPC-FWSN [12] . 为保证实验的可靠性和公平性,本文的实验结果均为算法在数据集上的最佳聚类结果. 在DPC-SKNN算法和上述对比算法中,IDPC-FA和DPC-CE算法不需要进行调参,其余7种算法均需要进行调参,表3给出这7种聚类算法的参数选取范围和步长. 在本节展示的9种算法在数据集的评价指标值的表内,“Par”表示算法在数据集上获得最佳聚类结果时的参数值. 实验的硬件环境均为11th Gen Intel(R)Core(TM)i5-11400H @ 2.70 GHz 2.69 GHz,16 G RAM,Windows 11的64位操作系统,编程环境为MATLAB R2022a.
调整互信息(adjusted mutual information,AMI)[30]、福尔克斯–马洛斯指数(fowlkes-mallows index,FMI)[31] 和调整兰德系数(adjusted rand index,ARI)[30] 是常用于评价聚类算法在数据集的聚类结果的指标,AMI和ARI指标的取值范围在[−1,1]之间,FMI 指标的取值范围在[0,1]之间,上述3个评价指标的数值越接近1代表聚类效果越好.
表3聚类算法参数设置
Table3Clustering algorithm parameter settings

4.2 流形数据集的实验结果分析
本小节分别使用算法在8个流形数据集上进行实验,并对实验结果进行分析. 表4给出了9种聚类算法在8个流形数据集的聚类结果,从表4可以看出,DPCSKNN算法在对Pathbased,Crossline和D6流形数据集聚类时,虽未能得到完全正确的结果,但与其他算法相比,获得的3个评价指标均为最大值. 因为DPCSKNN算法通过考虑K近邻、二阶K近邻在扩散过程所发挥的作用,能更好识别流形数据的分布特征,增强了同一类簇样本的相似性,从而获得更好的聚类结果. 对于剩下的5个流形数据集,DPC-SKNN算法能够准确识别类簇中心和分配样本,从而获得的聚类评价指标均为1.
表4在流形数据集上的评价指标
Table4Evaluation indexes on manifold datasets

(转下页)
(接上页)

图2展示了9种算法在Db数据集的聚类结果,图中的“六角星”表示算法找到的类簇中心. Db数据集包含4个曲线状的流形类簇,最长的“Z”形类簇形状十分曲折,易对算法在该类簇寻找类簇中心和分配样本造成严重干扰. 如图2所示,只有DPC-SKNN算法能将 “Z”形类簇与其余3个类簇区分开,通过考虑样本与其近邻样本间的关系,增强同一类簇样本间的相似性,将跨度较大的“Z”形类簇当做一个整体,从而在Db数据集完成准确聚类. 其余算法均未能取得最佳结果,在识别类簇中心和分配剩余样本的过程中出现不同程度的错误. 其中,RKNN-DPC算法虽能找到各类簇中心,但在分配“Z”形类簇上半部分样本时出现错误,导致聚类效果不佳. 其余7种算法均在“Z”形类簇找到两个类簇中心. DPC,SNN-DPC算法看似以水平线作为分界线将数据集左侧类簇和“Z”型类簇分为3个类簇,降低了聚类质量.
4.3 UCI数据集的实验结果与分析
在本小节,DPC-SKNN算法与8种算法在8个UCI 数据集上进行比较,9种算法在UCI数据集的聚类结果评价指标值如表5所示,可以发现DPC-SKNN算法获得了不错的聚类结果. 相比于其他算法,DPC-SKNN 算法在多个UCI数据集上的评价指标值有所提高. 对于Iris数据集,SNN-DPC算法获得的评价指标值最高,DPC-SKNN算法次之,除DPC-CE算法外,其他算法之间的聚类结果差异较小. 在Zoo数据集上,DPCSKNN算法获得的聚类结果最好,与DPC算法的聚类结果相比,DPC-SKNN算法的AMI指标提升了0.22,ARI指标更是提升了0.45,其原因为Zoo数据集的样本分布较分散,DPC算法在分配样本时出现大量错误. 对于Wine,Glass和Thy数据集,DPC-SKNN也表现出优秀的聚类性能,因为该算法的局部密度和分配策略都考虑了样本的分布情况,以及周围样本之间的相互影响,所以在数据集上获得较好的聚类结果. 在Ecoli 数据集上,DPC–SKNN算法的聚类效果仅次于IDPCFA和DPC-FWSN算法. 在Led数据集上,FNDPC获得最佳的聚类结果,DPC-SKNN和SNN-DPC算法稍逊前者,原因在于Led数据集样本分布在空间的各个角落,DPC-SKNN 算法未完全找出相同类簇的所有样本,导致最终聚类结果一般,但DPC-SKNN算法在该数据集获得的评价指标高于其余8种算法的平均水平.
5 总结
针对DPC算法处理流形数据集时存在的缺陷,本文提出一种面向流形数据的共享近邻和二阶K近邻密度峰值聚类(DPC-SKNN)算法,该算法具有以下特点: 1)提出一种基于共享近邻的局部密度,该局部密度定义方式不仅考虑了样本及其周围样本的距离关系和共享近邻区域对样本密度的影响,还考虑样本的逆近邻个数,有助于DPC-SKNN算法在数据集上选取正确类簇中心; 2)设计K近邻的分配策略,在分配剩余样本时,将样本关联关系分为3种情况,通过考虑K近邻在扩散过程所发挥的作用,增强了同一类簇样本的相似性,有效提高样本分配的准确率. 实验结果表明,DPC-SKNN算法在流形数据集上有着很好的聚类效果,在UCI数据集上的整体聚类效果也优于对比算法. 由于DPC-SKNN算法的参数K需人为选取,如何让算法根据不同数据集自动选取参数K 需进一步研究. 另外,如何提高算法处理高维海量数据[32]的效率也是今后研究的重点.

图2在Db数据集上的聚类结果
Fig.2Clustering results on Db dataset
表5在UCI数据集上的评价指标
Table5Evaluation indexes on UCI datasets

(转下页)
(接上页)
